集合
✅Java中有哪些集合类(容器)?
参考答案
Java中的集合类主要由Collection和Map这两个接口派生而出,其中Collection接口又派生出三个子接口,分别是Set、List、Queue。所有的Java集合类,都是Set、List、Queue、Map这四个接口的实现类,这四个接口将集合分成了四大类,其中
- Set代表无序的,元素不可重复的集合;
- List代表有序的,元素可以重复的集合;
- Queue代表先进先出(FIFO)的队列;
- Map代表具有映射关系(key-value)的集合。
这些接口拥有众多的实现类,其中最常用的实现类有HashSet、TreeSet、ArrayList、LinkedList、ArrayDeque、HashMap、TreeMap等。
扩展阅读
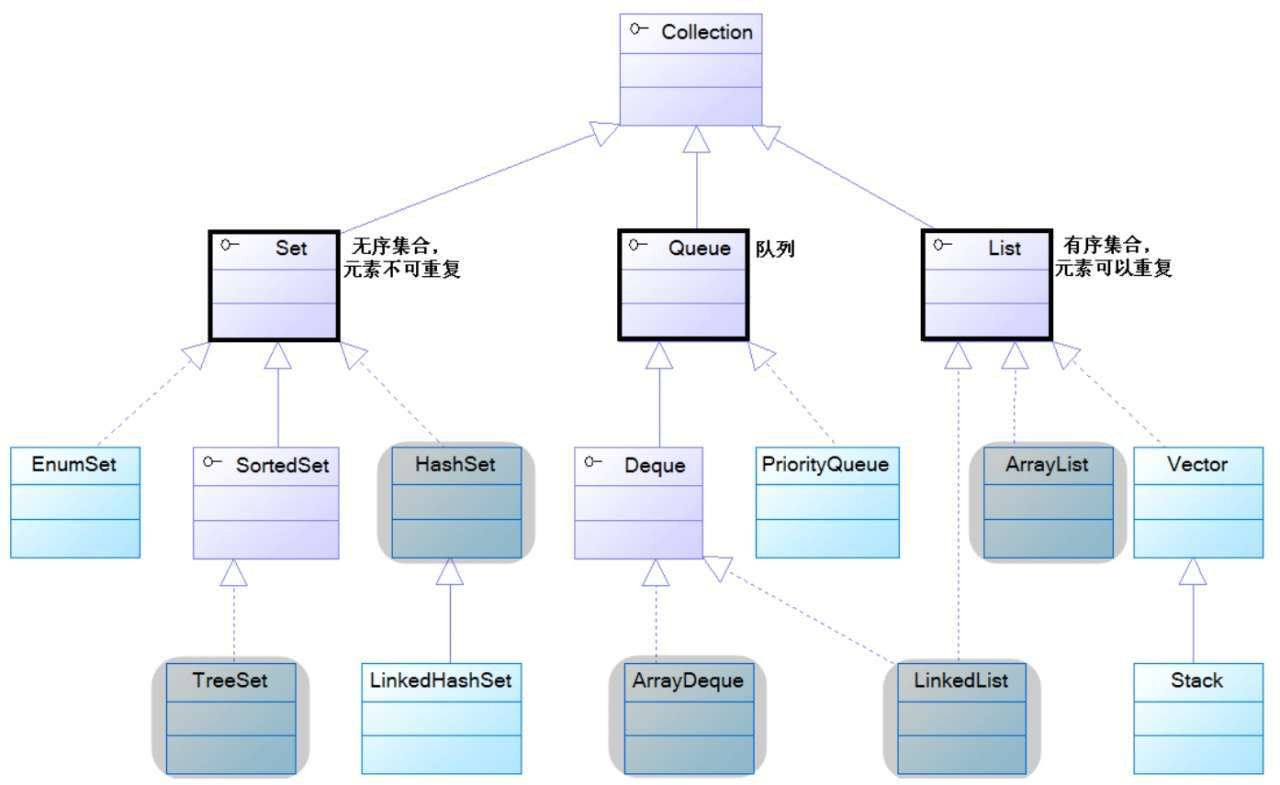
Collection又继承了lterable接口,Collection体系的继承树:
Map体系的继承树:
注:紫色框体代表接口,其中加粗的是代表四类集合的接口。蓝色框体代表实现类,其中有阴影的是常用实现类。
📚Collection和Collections有什么区别?
- Collection 是一个集合接口:它提供了对集合对象进行基本操作的通用接口方法。Collection接口在Java 类库中有很多具体的实现。是list,set等的父接口。
- Collections 是一个包装类:它包含有各种有关集合操作的静态多态方法。此类不能实例化,就像一个工具类,服务于Java的Collection框架。
📚Java中的Collection如何遍历迭代?
- 传统的for循环遍历,基于计数器的:遍历者自己在集合外部维护一个计数器,然后依次读取每一个位置的元素,当读取到最后一个元素后,停止。主要就是需要按元素的位置来读取元素。
- 迭代器遍历,Iterator:每一个具体实现的数据集合,一般都需要提供相应的
Iterator。相比于传统for循环,Iterator取缔了显式的遍历计数器。所以基于顺序存储集合的Iterator可以直接按位置访问数据。而基于链式存储集合的Iterator,正常的实现,都是需要保存当前遍历的位置。然后根据当前位置来向前或者向后移动指针。 - foreach循环遍历:根据反编译的字节码可以发现,
foreach内部也是采用了Iterator的方式实现,只不过Java编译器帮我们生成了这些代码。 - 迭代器遍历:Enumeration:
Enumeration接口是Iterator迭代器的“古老版本”,从JDK 1.0开始,Enumeration接口就已经存在了(Iterator从JDK 1.2才出现)
📚Iterable和Iterator如何使用?
Iterator和Iterable是两个接口,前者代表的是迭代的方式,如next和hasNext方法就是需要在该接口中实现。后者代表的是是否可以迭代,如果可以迭代,会返回Iterator接口,即返回迭代方式 常见的使用方式一般是集合实现Iterable表明该集合可以遍历,同时选择Iterator或者自定义一个Iterator的实现类去选择遍历方式,如:
class AbstractList<E> implements Iterable<E> {
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {}
}
📚为什么不把Iterable和Iterator合成一个使用
- 通过
Javadoc文档我们可以发现,Iterable和Iterator并不是同时出现的,Iterator于1.2就出现了,目的是为了代替Enumeration,而Iterable则是1.5才出现的 - 将是否可以迭代和迭代方式抽出来,更符合单一职责原则,如果抽出来,迭代方式就可以被多个可迭代的集合复用,更符合面向对象的特点。
🪟Map
✅Map接口有哪些实现类?
参考答案
Map接口有很多实现类,其中比较常用的有HashMap、LinkedHashMap、TreeMap、ConcurrentHashMap。
对于不需要排序的场景,优先考虑使用HashMap,因为它是性能最好的Map实现。如果需要保证线程安全,则可以使用ConcurrentHashMap。它的性能好于Hashtable,因为它在put时采用分段锁/CAS的加锁机制,而不是像Hashtable那样,无论是put还是get都做同步处理。
对于需要排序的场景,如果需要按插入顺序排序则可以使用LinkedHashMap,如果需要将key按自然顺序排列甚至是自定义顺序排列,则可以选择TreeMap。如果需要保证线程安全,则可以使用Collections工具类将上述实现类包装成线程安全的Map。
扩展阅读
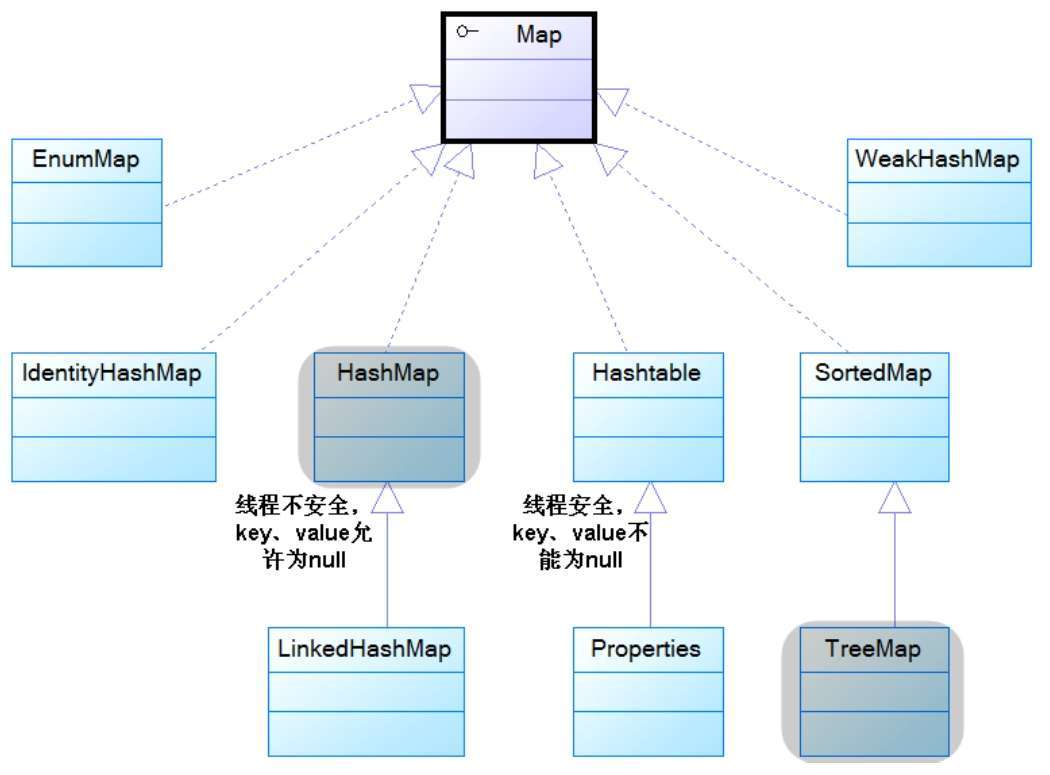
紫色框体代表接口。蓝色框体代表实现类,其中有阴影的是常用实现类。
✅HashMap有什么特点?
参考答案
- 性能比较好,但
HashMap是线程不安全的实现; HashMap可以使用null作为key或value。
✅ HashMap在get和put时经过哪些步骤?
面试经典问题:描述一下Map put的过程?
参考答案
HashMap是最经典的Map实现,下面以它的视角介绍put的过程:
首次扩容:
先判断数组是否为空,若数组为空则进行第一次扩容(resize);
计算索引:
通过hash算法,计算键值对在数组中的索引;
插入数据:
如果当前位置元素为空,则直接插入数据;
如果当前位置元素非空,且key已存在,则直接覆盖其value;
如果当前位置元素非空,且key不存在,则将数据链到链表末端;
若链表长度达到8,则将链表转换成红黑树,并将数据插入树中;
再次扩容
如果数组中元素个数(size)超过阈值(threshold),则再次进行扩容操作。
扩展阅读
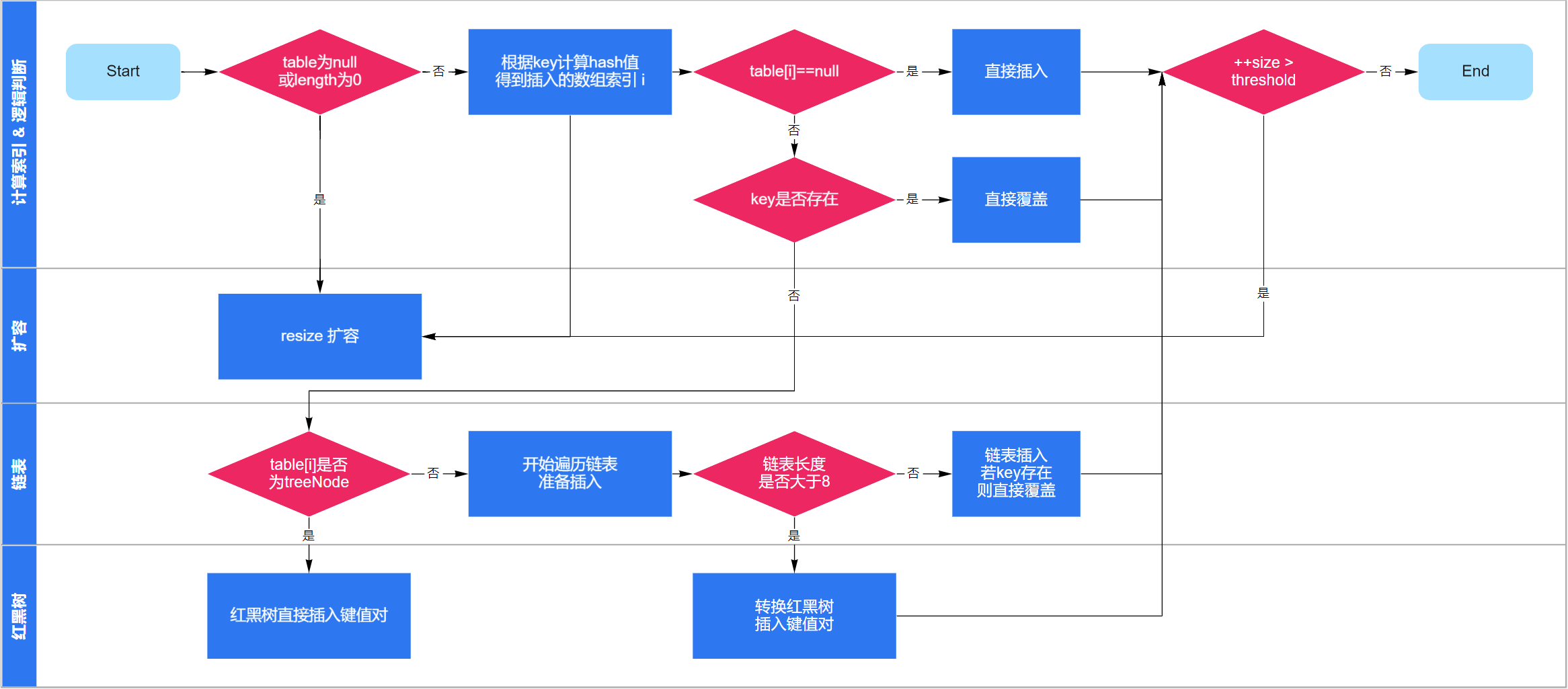
HashMap添加数据的详细过程,如下图:
📚HashMap如何定位key
先通过 (table.length - 1) & (key.hashCode ^ (key.hashCode >> 16))定位到key位于哪个table中,然后再通过key.equals(rowKey)来判断两个key是否相同,综上,是先通过hashCode和equals来定位KEY的。 源码如下:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
// ...省略
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 这里会通过equals判断
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// ...省略
return null;
}
所以,在使用HashMap的时候,尽量用String和Enum等已经实现过hashCode和equals方法的官方库类,如果一定要自己的类,就一定要实现hashCode和equals方法
📚HashMap定位tableIndex的骚操作
通过源码发现,hashMap定位tableIndex的时候,是通过(table.length - 1) & (key.hashCode ^ (key.hashCode >> 16)),而不是常规的key.hashCode % (table.length)呢?
- 为什么是用&而不是用%:因为&是基于内存的二进制直接运算,比转成十进制的取模快的多。以下运算等价:X % 2^n = X & (2^n – 1)。这也是hashMap每次扩容都要到2^n的原因之一
- 为什么用key.hash ^ (key.hash >> 16)而不是用key.hash:这是因为增加了扰动计算,使得hash分布的尽可能均匀。因为hashCode是int类型,虽然能映射40亿左右的空间,但是,HashMap的table.length毕竟不可能有那么大,所以为了使hash%table.length之后,分布的尽可能均匀,就需要对实例的hashCode的值进行扰动,说白了,就是将hashCode的高16和低16位,进行异或,使得hashCode的值更加分散一点。
📚HashMap的key为null时,没有hashCode是如何存储的?
HashMap对key=null的case做了特殊的处理,key值为null的kv对,总是会放在数组的第一个元素中,如下源码所示:
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
📚HashMap的value可以为null吗?有什么优缺点?
HashMap的key和value都可以为null,优点很明显,不会因为调用者的粗心操作就抛出NPE这种RuntimeException,但是缺点也很隐蔽,就像下面的代码一样:
// 调用远程RPC方法,获取map
Map<String, Object> map = remoteMethod.queryMap();
// 如果包含对应key,则进行业务处理
if(map.contains(KEY)) {
String value = (String)map.get(KEY);
System.out.println(value);
}
虽然map.contains(key),但是map.get(key)==null,就会导致后面的业务逻辑出现NPE问题
✅HashMap的put方法是如何实现的?
下面是JDK 1.8中HashMap的put方法的简要实现过程:
- 首先,put方法会计算键的哈希值(通过调用hash方法),并通过哈希值计算出在数组中的索引位置。
- 如果该位置上的元素为空,那么直接将键值对存储在该位置上。
- 如果该位置上的元素不为空,那么遍历该位置上的元素,如果找到了与当前键相等的键值对,那么将该键值对的值更新为当前值,并返回旧值。
- 如果该位置上的元素不为空,但没有与当前键相等的键值对,那么将键值对插入到链表或红黑树中(如果该位置上的元素数量超过了一个阈值,就会将链表转化为红黑树来提高效率)。
- 如果插入成功,返回null;如果插入失败,返回被替换的值。
- 插入成功后,如果需要扩容,那么就进行一次扩容操作。
源码解读
put方法的代码很简单,就一行代码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
核心其实是通过 putValue方法实现的,在传给putValue的参数中,先调用hash获取了一下hashCode。
putVal 方法主要实现如下,增加了注释:
/**
* Implements Map.put and related methods.
*
* @param hash key 的 hash 值
* @param key key 值
* @param value value 值
* @param onlyIfAbsent true:如果某个 key 已经存在那么就不插了;false 存在则替换,没有则新增。这里为 false
* @param evict 不用管了,我也不认识
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// tab 表示当前 hash 散列表的引用
Node<K, V>[] tab;
// 表示具体的散列表中的元素
Node<K, V> p;
// n:表示散列表数组的长度
// i:表示路由寻址的结果
int n, i;
// 将 table 赋值发给 tab ;如果 tab == null,说明 table 还没有被初始化。则此时是需要去创建 table 的
// 为什么这个时候才去创建散列表?因为可能创建了 HashMap 时候可能并没有存放数据,如果在初始化 HashMap 的时候就创建散列表,势必会造成空间的浪费
// 这里也就是延迟初始化的逻辑
if ((tab = table) == null || (n = tab.length) == 0) {
n = (tab = resize()).length;
}
// 如果 p == null,说明寻址到的桶的位置没有元素。那么就将 key-value 封装到 Node 中,并放到寻址到的下标为 i 的位置
if ((p = tab[i = (n - 1) & hash]) == null) {
tab[i] = newNode(hash, key, value, null);
}
// 到这里说明 该位置已经有数据了,且此时可能是链表结构,也可能是树结构
else {
// e 表示找到了一个与当前要插入的key value 一致的元素
Node<K, V> e;
// 临时的 key
K k;
// p 的值就是上一步 if 中的结果即:此时的 (p = tab[i = (n - 1) & hash]) 不等于 null
// p 是原来的已经在 i 位置的元素,且新插入的 key 是等于 p中的key
//说明找到了和当前需要插入的元素相同的元素(其实就是需要替换而已)
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
//将 p 的值赋值给 e
e = p;
//说明已经树化,红黑树会有单独的文章介绍,本文不再赘述
else if (p instanceof TreeNode) {
e = ((TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value);
} else {
//到这里说明不是树结构,也不相等,那说明不是同一个元素,那就是链表了
for (int binCount = 0; ; ++binCount) {
//如果 p.next == null 说明 p 是最后一个元素,说明,该元素在链表中也没有重复的,那么就需要添加到链表的尾部
if ((e = p.next) == null) {
//直接将 key-value 封装到 Node 中并且添加到 p的后面
p.next = newNode(hash, key, value, null);
// 当元素已经是 7了,再来一个就是 8 个了,那么就需要进行树化
if (binCount >= TREEIFY_THRESHOLD - 1) {
treeifyBin(tab, hash);
}
break;
}
//在链表中找到了某个和当前元素一样的元素,即需要做替换操作了。
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) {
break;
}
//将e(即p.next)赋值为e,这就是为了继续遍历链表的下一个元素(没啥好说的)下面有张图帮助大家理解。
p = e;
}
}
//如果条件成立,说明找到了需要替换的数据,
if (e != null) {
//这里不就是使用新的值赋值为旧的值嘛
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null) {
e.value = value;
}
//这个方法没用,里面啥也没有
afterNodeAccess(e);
//HashMap put 方法的返回值是原来位置的元素值
return oldValue;
}
}
// 上面说过,对于散列表的 结构修改次数,那么就修改 modCount 的次数
++modCount;
//size 即散列表中的元素的个数,添加后需要自增,如果自增后的值大于扩容的阈值,那么就触发扩容操作
if (++size > threshold) {
resize();
}
//啥也没干
afterNodeInsertion(evict);
//原来位置没有值,那么就返回 null 呗
return null;
}
✅HashMap的get方法是如何实现的?
下面是JDK 1.8中HashMap的get方法的简要实现过程:
- 首先,需要计算键的哈希值,并通过哈希值计算出在数组中的索引位置。
- 如果该位置上的元素为空,说明没有找到对应的键值对,直接返回null。
- 如果该位置上的元素不为空,遍历该位置上的元素,如果找到了与当前键相等的键值对,那么返回该键值对的值。
- 如果该位置上的元素不为空,但没有与当前键相等的键值对,那么就需要在链表或红黑树中继续查找。
- 遍历链表或红黑树,查找与当前键相等的键值对,找到则返回该键值对的值,否则返回null。
源码解读
public V get(Object key) {
Node<K, V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
get 方法看起来很简单,就是通过同样的 hash 得到 key 的hash 值。重点看下 getNode方法:
final Node<K, V> getNode(int hash, Object key) {
//当前HashMap的散列表的引用
Node<K, V>[] tab;
//first:桶头元素
//e:用于存放临时元素
Node<K, V> first, e;
//n:table 数组的长度
int n;
//元素中的 k
K k;
// 将 table 赋值为 tab,不等于null 说明有数据,(n = tab.length) > 0 同理说明 table 中有数据
//同时将 改位置的元素 赋值为 first
if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) {
//定位到了桶的到的位置的元素就是想要获取的 key 对应的,直接返回该元素
if (first.hash == hash && ((k = first.key) == key || (key != null && key.equals(k)))) {
return first;
}
//到这一步说明定位到的元素不是想要的,且改位置不仅仅有一个元素,需要判断是链表还是树
if ((e = first.next) != null) {
//是否已经树化
if (first instanceof TreeNode) {
return ((TreeNode<K, V>) first).getTreeNode(hash, key);
}
//处理链表的情况
do {
//如果遍历到了就直接返回该元素
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) {
return e;
}
} while ((e = e.next) != null);
}
}
//遍历不到返回null
return null;
}
✅HashMap的remove方法是如何实现的?
下面是JDK 1.8中HashMap的remove方法的简要实现过程:
- 首先,remove方法会计算键的哈希值,并通过哈希值计算出在数组中的索引位置。
- 如果该位置上的元素为空,说明没有找到对应的键值对,直接返回null。
- 如果该位置上的元素不为空,检查是否与当前键相等,如果相等,那么将该键值对删除,并返回该键值对的值。
- 如果该位置上的元素不为空,但也与当前键不相等,那么就需要在链表或红黑树中继续查找。
- 遍历链表或者红黑树,查找与当前键相等的键值对,找到则将该键值对删除,并返回该键值对的值,否则返回null。
源码解读
public V remove(Object key) {
Node<K, V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
重点还是来看下 removeNode 方法:
/**
* Implements Map.remove and related methods.
*
* @param hash hash 值
* @param key key 值
* @param value value 值
* @param matchValue 是否需要值匹配 false 表示不需要
* @param movable 不用管
* @return the node, or null if none
*/
final Node<K, V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) {
//当前HashMap 中的散列表的引用
Node<K, V>[] tab;
//p:表示当前的Node元素
Node<K, V> p;
// n:table 的长度
// index:桶的下标位置
int n, index;
//(tab = table) != null && (n = tab.length) > 0 条件成立,说明table不为空(table 为空就没必要执行了)
// p = tab[index = (n - 1) & hash]) != null 将定位到的捅位的元素赋值给 p ,并判断定位到的元素不为空
if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) {
//进到 if 里面来了,说明已经定位到元素了
//node:保存查找到的结果
//e:表示当前元素的下一个元素
Node<K, V> node = null, e;
K k;
V v;
// 该条件如果成立,说明当前的元素就是要找的结果(这是最简单的情况,这个是很好理解的)
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) {
node = p;
}
//到这一步,如果 (e = p.next) != null 说明该捅位找到的元素可能是链表或者是树,需要继续判断
else if ((e = p.next) != null) {
//树,不考虑
if (p instanceof TreeNode) {
node = ((TreeNode<K, V>) p).getTreeNode(hash, key);
}
//处理链表的情况
else {
do {
//如果条件成立,说明已经匹配到了元素,直接将查找到的元素赋值给 node,并跳出循环(总体还是很好理解的)
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) {
node = e;
break;
}
//将正在遍历的当前的临时元素 e 赋值给 p
p = e;
} while ((e = e.next) != null);
}
}
// node != null 说明匹配到了元素
//matchValue为false ,所以!matchValue = true,后面的条件直接不用看了
if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) {
//树,不考虑
if (node instanceof TreeNode) {
((TreeNode<K, V>) node).removeTreeNode(this, tab, movable);
}
// 这种情况是上面的最简单的情况
else if (node == p) {
//直接将当前节点的下一个节点放在当前的桶位置(注意不是下一个桶位置,是该桶位置的下一个节点)
tab[index] = node.next;
} else {
//说明定位到的元素不是该桶位置的头元素了,那直接进行一个简单的链表的操作即可
p.next = node.next;
}
//移除和添加都属于结构的修改,需要同步自增 modCount 的值
++modCount;
//table 中的元素个数减 1
--size;
//啥也没做,不用管
afterNodeRemoval(node);
//返回被移除的节点元素
return node;
}
}
//没有匹配到返回null 即可
return null;
}
另外 remove 还有一个方法是key 和 value 都需要匹配上才移除。
public boolean remove(Object key, Object value) {
return removeNode(hash(key), key, value, true, true) != null;
}
这个关键点就是这句话
// (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))
//matchValue = true,所以 !matchValue = false,所以此时必须保证后面的值是true 才执行真正的 remove 操作
if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) {
}
✅HashMap的hash方法是如何实现的?
hash方法的功能是根据Key来定位这个K-V在链表数组中的位置的。也就是hash方法的输入应该是个Object类型的Key,输出应该是个int类型的数组下标。 最简单的话,我们只要调用Object对象的hashCode()方法,该方法会返回一个整数,然后用这个数对HashMap或者HashTable的容量进行取模就行了。只不过,在具体实现上,考虑到效率等问题,HashMap的实现会稍微复杂一点。他的具体实现主要由两个方法int hash(Object k)和int indexFor(int h, int length)来实现的(JDK 1.8中不再单独有indexFor方法,但是在计算具体的table index时也用到了一样的算法逻辑,具体代码可以看putVal方法)。
hash :该方法主要是将Object转换成一个整型。 indexFor :该方法主要是将hash生成的整型转换成链表数组中的下标。`
在这里面,HashMap的hash方法为了提升效率,主要用到了以下技术手段:
1、使用位运算(&)来代替取模运算(%),因为位运算(&)效率要比代替取模运算(%)高很多,主要原因是位运算直接对内存数据进行操作,不需要转成十进制,因此处理速度非常快。 2、对hashcode进行扰动计算,防止不同hashCode的高位不同但低位相同导致的hash冲突。简单点说,就是为了把高位的特征和低位的特征组合起来,降低哈希冲突的概率,也就是说,尽量做到任何一位的变化都能对最终得到的结果产生影响。
扩展阅读
📚使用&代替%运算
不知道,大家有没有想过,为什么可以使用位运算(&)来实现取模运算(%)呢? 这实现的原理如下:
X % 2^n = X & (2^n - 1)
2^n 表示2的n次方,也就是说,一个数对2^n取模 == 一个数和(2^n - 1)做按位与运算 。
假设n为3,则2^3 = 8,表示成2进制就是1000。2^3 -1 = 7 ,即0111。
此时X & (2^3 - 1) 就相当于取X的2进制的最后三位数。
从2进制角度来看,X / 8相当于 X >> 3,即把X右移3位,此时得到了X / 8的商,而被移掉的部分(后三位),则是X % 8,也就是余数。
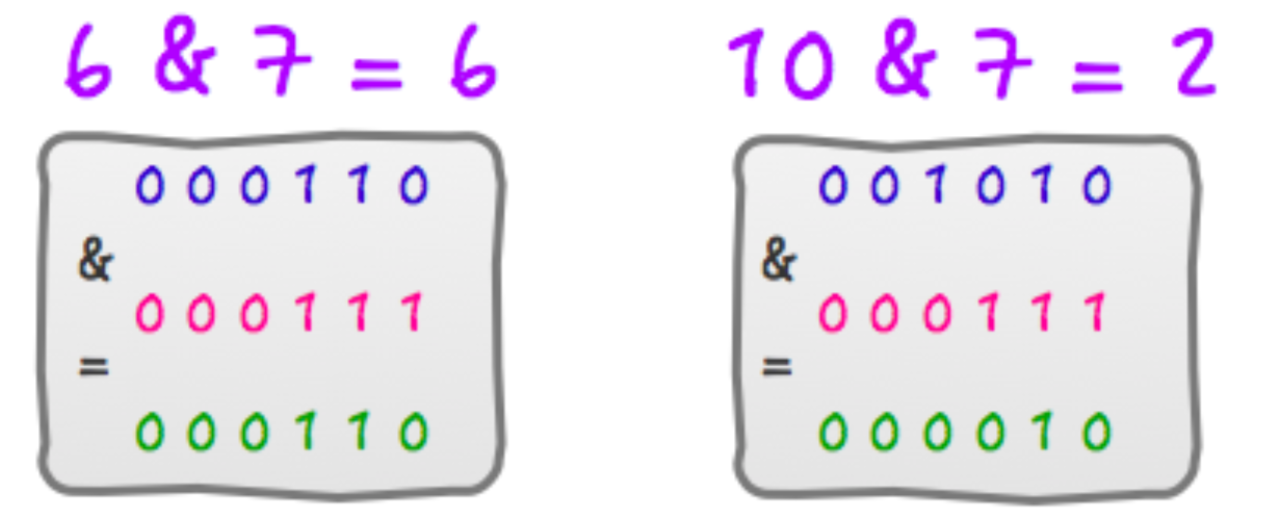
上面的解释不知道你有没有看懂,没看懂的话其实也没关系,你只需要记住这个技巧就可以了。或者你可以找几个例子试一下。
6 % 8 = 6 ,6 & 7 = 6
10 % 8 = 2 ,10 & 7 = 2
所以,return h & (length-1);只要保证length的长度是2^n的话,就可以实现取模运算了。而HashMap中的length也确实是2的倍数,初始值是16,之后每次扩充为原来的2倍。
总结一下,HashMap的数据是存储在链表数组里面的。在对HashMap进行插入/删除等操作时,都需要根据K-V对的键值定位到他应该保存在数组的哪个下标中。而这个通过键值求取下标的操作就叫做哈希。HashMap的数组是有长度的,Java中规定这个长度只能是2的倍数,初始值为16。简单的做法是先求取出键值的hashcode,然后在将hashcode得到的int值对数组长度进行取模。为了考虑性能,Java总采用按位与操作实现取模操作。 其实,使用位运算代替取模运算,除了性能之外,还有一个好处就是可以很好的解决负数的问题。因为我们知道,hashcode的结果是int类型,而int的取值范围是-2^31 ~ 2^31 - 1,即[ -2147483648, 2147483647];这里面是包含负数的,我们知道,对于一个负数取模还是有些麻烦的。如果使用二进制的位运算的话就可以很好的避免这个问题。首先,不管hashcode的值是正数还是负数。length-1这个值一定是个正数。那么,他的二进制的第一位一定是0(有符号数用最高位作为符号位,“0”代表“+”,“1”代表“-”),这样里两个数做按位与运算之后,第一位一定是个0,也就是,得到的结果一定是个正数。
📚扰动计算
其实,无论是用取模运算还是位运算都无法直接解决冲突较大的问题。 比如:CA11 0000和0001 0000在对0000 1111进行按位与运算后的值是相等的。
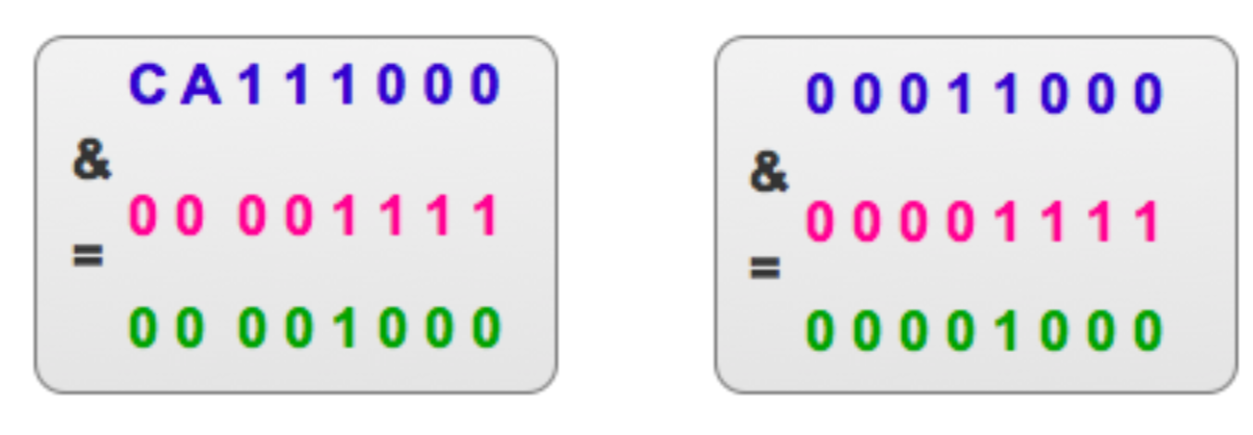
两个不同的键值,在对数组长度进行按位与运算后得到的结果相同,这不就发生了冲突吗。那么如何解决这种冲突呢,来看下Java是如何做的。 其中的主要代码部分如下:
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
这段代码是为了对key的hashCode进行扰动计算,防止不同hashCode的高位不同但低位相同导致的hash冲突。简单点说,就是为了把高位的特征和低位的特征组合起来,降低哈希冲突的概率,也就是说,尽量做到任何一位的变化都能对最终得到的结果产生影响。 举个例子来说,我们现在想向一个HashMap中put一个K-V对,Key的值为“hollischuang”,经过简单的获取hashcode后,得到的值为“1011000110101110011111010011011”,如果当前HashTable的大小为16,即在不进行扰动计算的情况下,他最终得到的index结果值为11。由于15的二进制扩展到32位为“00000000000000000000000000001111”,所以,一个数字在和他进行按位与操作的时候,前28位无论是什么,计算结果都一样(因为0和任何数做与,结果都为0)。如下图所示。
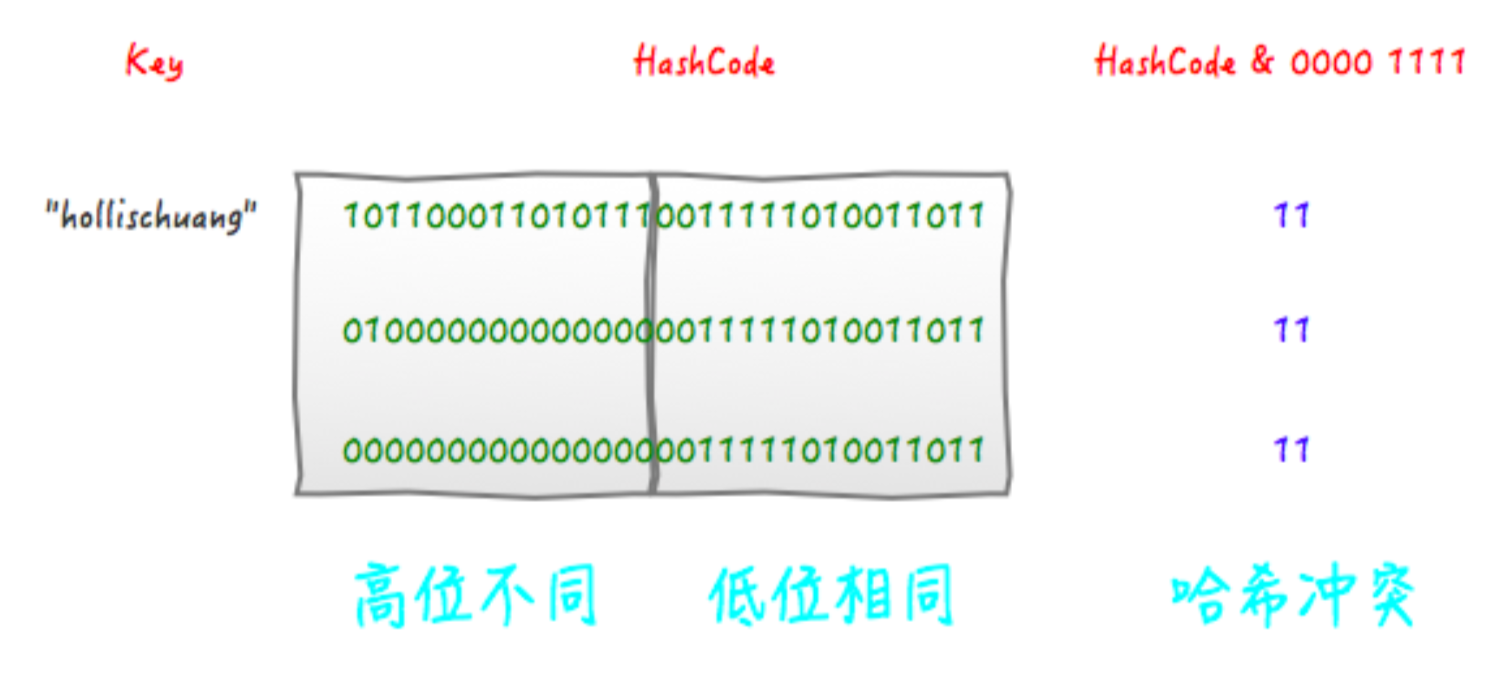
可以看到,后面的两个hashcode经过位运算之后得到的值也是11 ,虽然我们不知道哪个key的hashcode是上面例子中的那两个,但是肯定存在这样的key,这就产生了冲突。 那么,接下来,我看看一下经过扰动的算法最终的计算结果会如何。

从上面图中可以看到,之前会产生冲突的两个hashcode,经过扰动计算之后,最终得到的index的值不一样了,这就很好的避免了冲突。
✅hash冲突通常怎么解决?
常见的四种方法:
开放定址法
- 开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。
链地址法
- 将哈希表的每个单元作为链表的头结点,所有哈希地址为i的元素构成一个同义词链表。即发生冲突时就把该关键字链在以该单元为头结点的链表的尾部。
再哈希法
- 当哈希地址发生冲突用其他的函数计算另一个哈希函数地址,直到冲突不再产生为止。4.建立公共溢出区将哈希表分为基本表和溢出表两部分,发生冲突的元素都放入溢出表中。
建立公共溢出区 ○将哈希表分为基本表和溢出表两部分,发生冲突的元素都放入溢出表中。
✅ HashMap是如何解决哈希冲突的?
参考答案
为了解决碰撞,当链表长度到达一个阈值8时,会将链表转换成红黑树提高性能。而当链表长度缩小到另一个阈值6时,又会将红黑树转换回单向链表提高性能。
✅JDK7和JDK8中的HashMap有什么区别?
参考答案
JDK7中的HashMap,是基于数组+链表来实现的,它的底层维护一个Entry数组。它会根据计算的hashCode将对应的KV键值对存储到该数组中,一旦发生hashCode冲突,那么就会将该KV键值对放到对应的已有元素的后面, 此时便形成了一个链表式的存储结构。
JDK7中HashMap的实现方案有一个明显的缺点,即当Hash冲突严重时,在桶上形成的链表会变得越来越长,这样在查询时的效率就会越来越低,其时间复杂度为O(N)。
JDK8中的HashMap,是基于数组+链表+红黑树来实现的,它的底层维护一个Node数组。当链表的存储的数据个数大于等于8的时候,不再采用链表存储,而采用了红黑树存储结构。这么做主要是在查询的时间复杂度上进行优化,链表为O(N),而红黑树一直是O(logN),可以大大的提高查找性能。
✅为什么在JDK8中HashMap要转成红黑树
📚为什么不继续使用链表
我们知道,HashMap解决hash冲突是通过拉链法完成的,在JDK8之前,如果产生冲突,就会把新增的元素增加到当前桶所在的链表中。 这样就会产生一个问题,当某个bucket冲突过多的时候,其指向的链表就会变得很长,这样如果put或者get该bucket上的元素时,复杂度就无限接近于O(N),这样显然是不可以接受的。 所以在JDK1.7的时候,在元素put之前做hash的时候,就会充分利用扰动函数,将不同KEY的hash尽可能的分散开。不过这样做起来效果还不是太好,所以当链表过长的时候,我们就要对其数据结构进行修改。
📚为什么是红黑树
当元素过多的时候,用什么来代替链表呢?我们很自然的就能想到可以用二叉树查找树代替,所谓的二叉查找树,一定是left < root < right,这样我们遍历的时间复杂度就会由链表的O(N)变为二叉查找树的O(logN),二叉查找树如下所示:
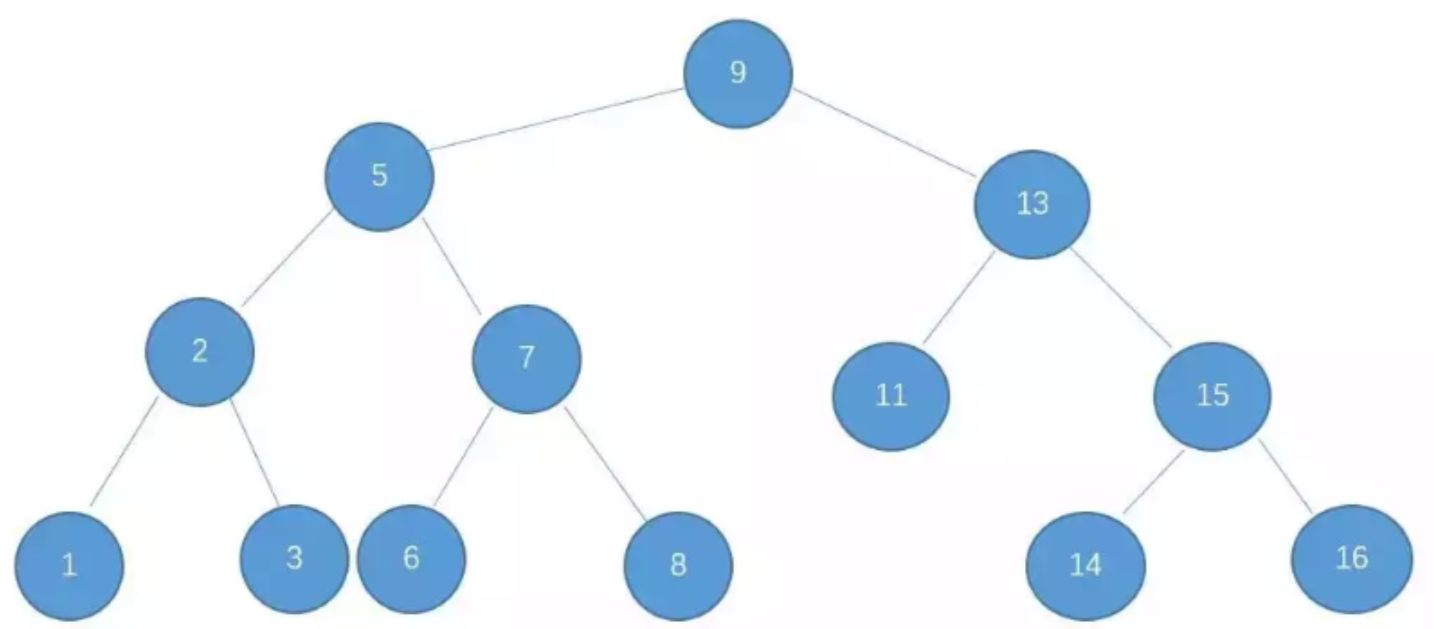
但是,对于极端情况,当子节点都比父节点大或者小的时候,二叉查找树又会退化成链表,查询复杂度会重新变为O(N),如下所示:
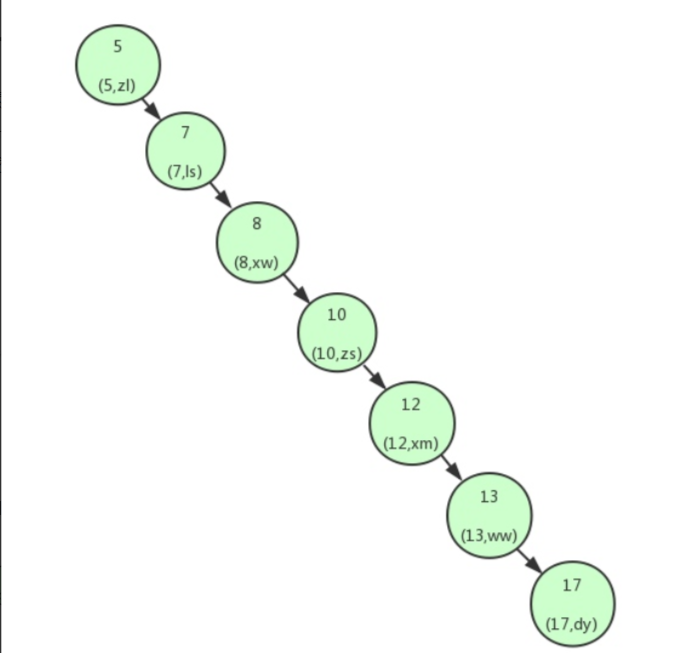
所以,我们就需要二叉平衡树出场,他会在每次插入操作时来检查每个节点的左子树和右子树的高度差至多等于1,如果>1,就需要进行左旋或者右旋操作,使其查询复杂度一直维持在O(logN)。 但是这样就万无一失了吗?其实并不然,我们不仅要保证查询的时间复杂度,还需要保证插入的时间复杂度足够低,因为平衡二叉树要求高度差最多为1,非常严格,导致每次插入都需要左旋或者右旋,极大的消耗了插入的时间。
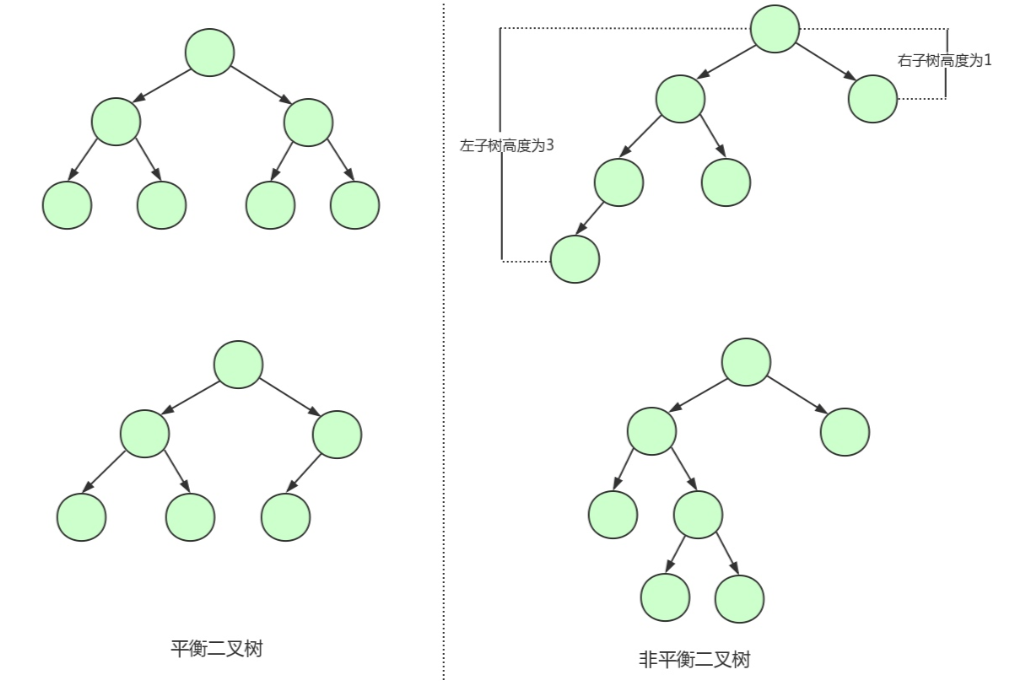
对于那些插入和删除比较频繁的场景,AVL树显然是不合适的。为了保证查询和插入的时间复杂度维持在一个均衡的水平上,所以就引入了红黑树。 在红黑树中,所有的叶子节点都是黑色的的空节点,也就是叶子节点不存数据;任何相邻的节点都不能同时为红色,红色节点是被黑色节点隔开的,每个节点,从该节点到达其可达的叶子节点的所有路径,都包含相同数目的黑色节点。 我们可以得到如下结论:红黑树不会像AVL树一样追求绝对的平衡,它的插入最多两次旋转,删除最多三次旋转,在频繁的插入和删除场景中,红黑树的时间复杂度,是优于AVL树的。
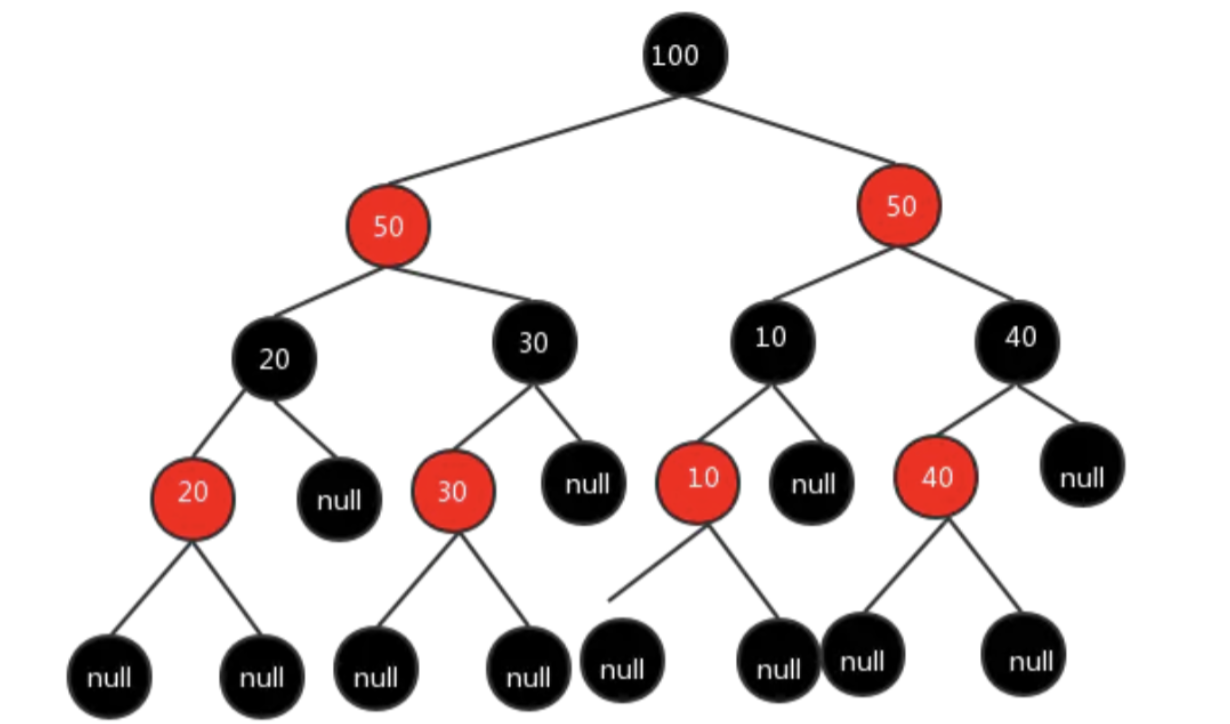
综上所述,这就是HashMap选择红黑树的原因。
扩展阅读
📚为什么是链表长度达到8的时候转
这个问题有两层含义,第一个是为什么不在冲突的时候立刻转为红黑树,第二个是为什么是达到8的时候转
📚为什么不在冲突的时候立刻转
原因有2,从空间维度来讲,因为红黑树的空间是普通链表节点空间的2倍,立刻转为红黑树后,太浪费空间;从时间维度上讲,红黑树虽然查询比链表快,但是插入比链表慢多了,每次插入都要旋转和变色,如果小于8就转为红黑树,时间和空间的综合平衡上就没有链表好。
📚为什么长度为8的时候转
先来看源码的一段注释:
/* Because TreeNodes are about twice the size of regular nodes, we
* use them only when bins contain enough nodes to warrant use
* (see TREEIFY_THRESHOLD). And when they become too small (due to
* removal or resizing) they are converted back to plain bins. In
* usages with well-distributed user hashCodes, tree bins are
* rarely used. Ideally, under random hashCodes, the frequency of
* nodes in bins follows a Poisson distribution
* (http://en.wikipedia.org/wiki/Poisson_distribution) with a
* parameter of about 0.5 on average for the default resizing
* threshold of 0.75, although with a large variance because of
* resizing granularity. Ignoring variance, the expected
* occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
* factorial(k)). The first values are:
*
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million
*/
大概的翻译就是TreeNode占用的内存是Node的两倍,只有在node数量达到8时才会使用它,而当 node 数量变小时(删除或者扩容),又会变回普通的 Node 。当 hashCode遵循泊松分布时,长度为 8 时的概率为 0.00000006 。官方认为这个概率足够的低,所以指定链表长度为 8 时转化为红黑树。所以 8 这个数是经过数学推理的,不是瞎写的。
📚为什么长度为6的时候转回来?
但是,当红黑树节点数小于 6 时,又会把红黑树转换回链表,这个设计的主要原因是出于对于性能和空间的考虑。前面讲过为什么直接用红黑树,那同理,转成红黑树之后总要在适当的时机转回来,要不然无论是空间占用大,而且插入性能都会下降。 8的时候转成红黑树,那么如果小于8立刻转回去,那么就可能会导致频繁转换,所以要选一个小于8的值,但是又不能是7。而通过前面提到的泊松分布可以看到,当红黑树节点数小于 6 时,它所带来的优势其实就是已经没有那么大了,就不足以抵消由于红黑树维护节点所带来的额外开销,此时转换回链表能够节省空间和时间。 但是不管怎样,6 这个数值是通过大量实验得到的经验值,在绝大多数情况下取得比较好的效果。
📚双向链表是怎么回事
HashMap红黑树的数据结构中,不仅有常见的parent,left,right节点,还有一个next和prev节点。这很明显的说明,其不仅是一个红黑树,还是一个双向链表,为什么是这样呢? 这个其实我们也在之前红黑树退化成链表的时候稍微提到过,红黑树会记录树化之前的链表结构,这样当红黑树退化成链表的时候,就可以直接按照链表重新链接的方式进行(详细分析可以见前面扩容的文章) 不过可能有人会问,那不是需要一个next节点就行了,为什么还要prev节点呢?这是因为当删除红黑树中的某个节点的时候,这个节点可能就是原始链表的中间节点,如果把该节点删除,只有next属性是没办法将原始的链表重新链接的,所以就需要prev节点,找到上一个节点,重新成链。
HashMap的元素没有比较能力,红黑树为什么可以比较?
这里红黑树使用了一个骚操作:
- 如果元素实现了
comparable接口,则直接比较,否则 - 则使用默认的仲裁方法,该方法的源码如下:
static int tieBreakOrder(Object a, Object b) {
int d;
if (a == null || b == null ||
(d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0)
d = (System.identityHashCode(a) <= System.identityHashCode(b) ?
-1 : 1);
return d;
}
✅ 介绍一下HashMap底层的实现原理
参考答案
- 它基于
hash算法,通过put和get方法来存储和获取对象。 - 底层的数据结构主要有数组+链表+红黑树。
- 在存储对象时,调用
put方法,根据K计算hashCode值从而得到bucket位置,进一步存储,如果出现hash冲突,则放在后面形成链表,当链表的长度达到阈值8时,就会形成红黑树,当数量减少到6会转换为链表,从而提高速度。 - 获取对象时,我们将
K传给get,它调用hashCode计算hash从而得到bucket位置,并进一步调用equals()方法确定键值对。
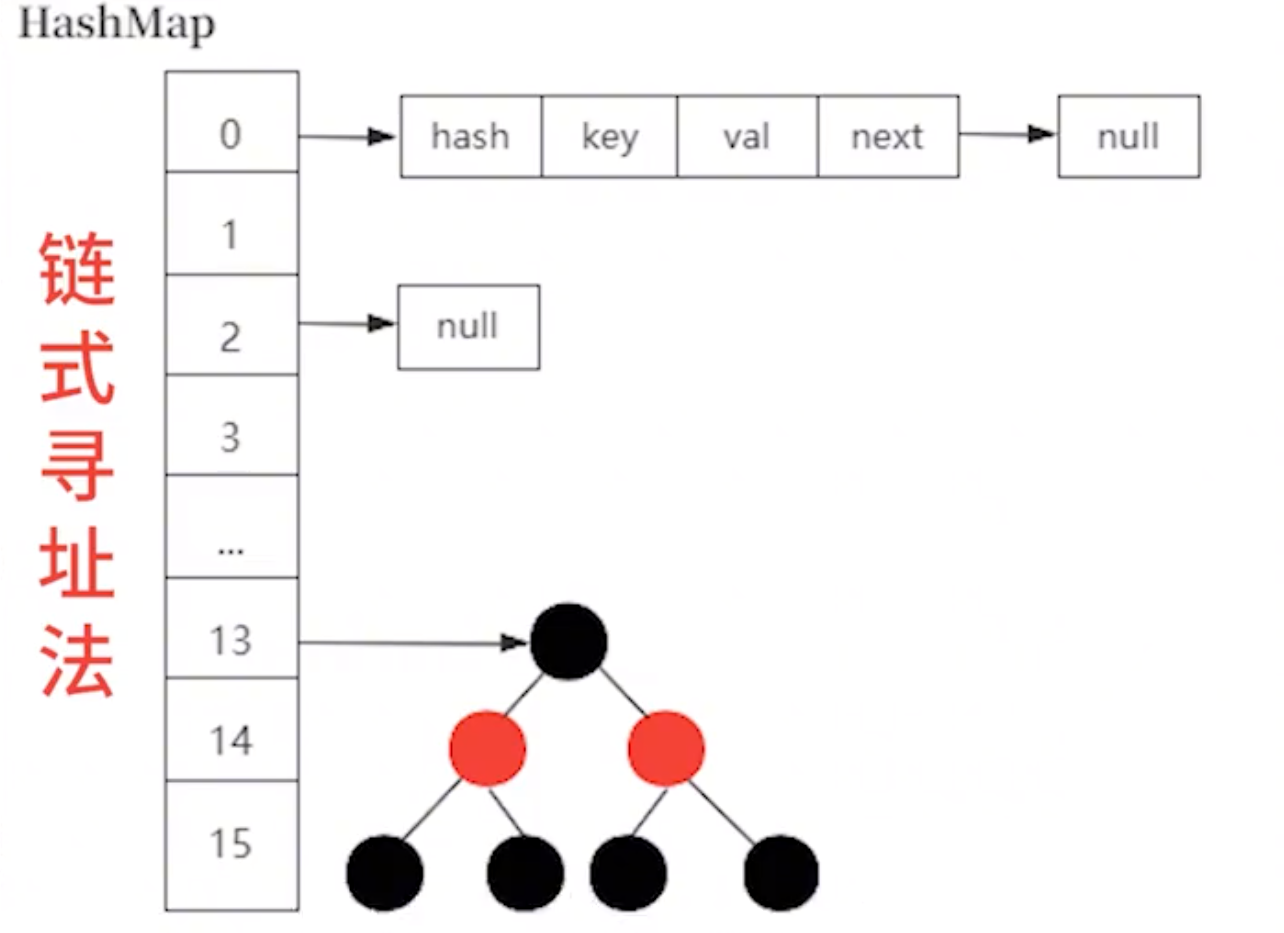
✅ 介绍一下HashMap的扩容机制
参考答案
📚HashMap的扩容机制主要涉及两个概念:负载因子和阈值。
- 负载因子(Load Factor):负载因子是**
HashMap中存储元素的数量与HashMap容量的比值**。负载因子的默认值为0.75,这是一个经验值,可以在一定程度上平衡空间和时间的消耗。 - 阈值(Threshold):阈值是
HashMap中的一个参数,用于判断是否需要进行扩容。当HashMap中存储的元素数量超过阈值时,就会触发扩容操作。阈值的计算公式为:阈值 = 负载因子 * 当前容量。
📚HashMap什么时候扩容? 当HashMap的元素达到阈值时,就会触发扩容操作,为原来的两倍。
📚HashMap的负载因子为什么是0.75?
前面说过这是一个经验值,可以在一定程度上平衡空间和时间的消耗。为什么呢?
负载因子表示Hash表元素的填充程度,负载因子值越大就会导致阈值越大,意味着触发扩容元素的个数会增加,虽然它的整体空间利用率比较高,但是hash冲突的概率也会增加。比如说容量为100,负载因子是0.75,这个时候只需要元素数量达到75就会触发扩容操作,如果负载因子增加到0.9,这个时候需要元素个数达到90才会触发扩容操作,比原来多了15容量,在这期间hash冲突的概率肯定随之增加。
反过来说,负载因子值越小,触发扩容元素的个数会减小,这意味着hash冲突的概率也会减小,但是对于内存空间的浪费就比较多了,还会增加扩容的一个频率,所以负载因子的设置本质上就是一个冲突的概率,以及空间利用率之间的一个平衡,所以0.75是经验性的选择,旨在平衡HashMap的空间利用率和性能。
我们知道HashMap是采用链式寻址法来解决hash冲突的问题,为了避免链表过长带来的时间复杂度过长的情况,所以链表长度>=7的时候就会转换为红黑树来提高检索效率,当负载因子在0.75的时候,链表的长度达到8的可能性几乎为0,比较好的达到了空间成本和时间成本的平衡。
扩展阅读
HashMap中链表转换为红黑树的阈值是8,红黑树转换为链表的阈值是6。
HashMap的默认初始容量为16,默认的加载因子为0.75,即当HashMap中元素个数超过容量的75%时,会进行扩容操作。扩容时,容量会扩大为原来的两倍,并将原来的元素重新分配到新的桶中。
Hashtable,默认初始容量为11,默认的加载因子为0.75,即当Hashtable中元素个数超过容量的75%时,会进行扩容操作。扩容时,容量会扩大为原来的两倍加1,并将原来的元素重新分配到新的桶中。
ConcurrentHashMap,默认初始容量为16,默认的加载因子为0.75,即当ConcurrentHashMap中元素个数超过容量的75%时,会进行扩容操作。扩容时,容量会扩大为原来的两倍,并会采用分段锁机制,将ConcurrentHashMap分为多个段(segment),每个段独立进行扩容操作,避免了整个ConcurrentHashMap的锁竞争。
✅2.10 HashMap中的循环链表是如何产生的?
参考答案
在多线程的情况下,当重新调整HashMap大小的时候,就会存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历。如果条件竞争发生了,那么就会产生死循环了。
✅2.11 HashMap为什么用红黑树而不用B树?
参考答案
HashMap本来是数组+链表的形式,链表由于其查找慢的特点,所以需要被查找效率更高的树结构来替换。如果用B/B+树的话,在数据量不是很多的情况下,数据都会“挤在”一个结点里面,这个时候遍历效率就退化成了链表。使其复杂度变回O(N),降低查询效率。
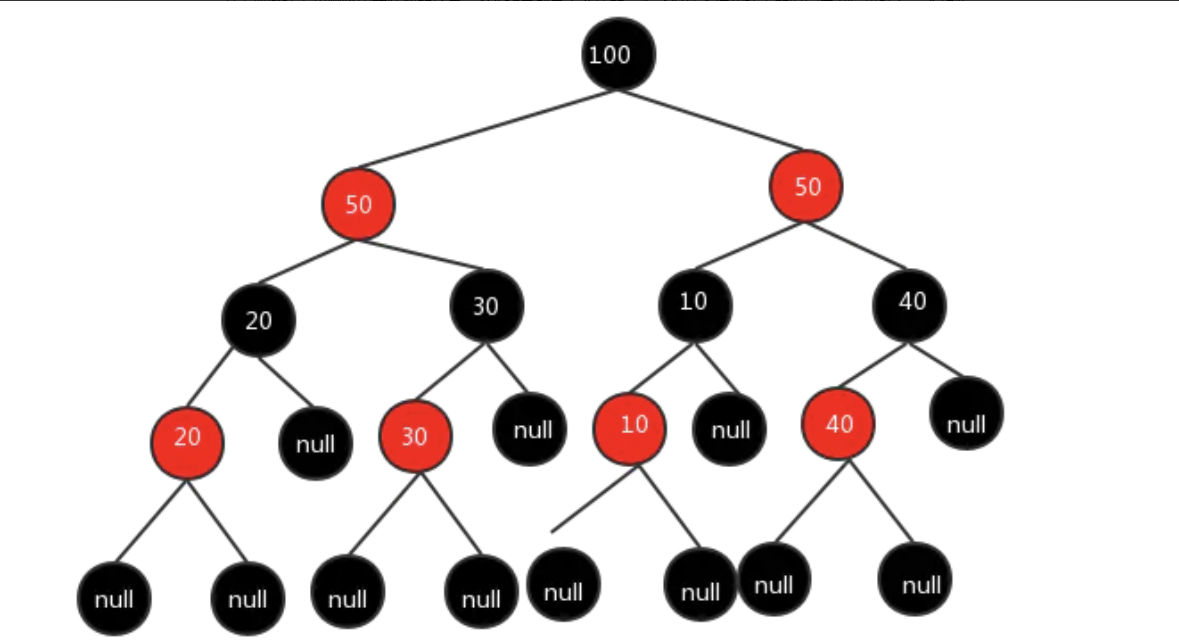
在红黑树中,所有的叶子节点都是黑色的的空节点,也就是叶子节点不存数据;任何相邻的节点都不能同时为红色,红色节点是被黑色节点隔开的,每个节点,从该节点到达其可达的叶子节点的所有路径,都包含相同数目的黑色节点,这种情况退化为链表的概率非常低,所以选择红黑树。
✅2.Java中的集合哪些是线程安全和线程不安全的?
参考答案
在java.util包下的集合类大部分都是线程不安全的。
例如我们常用的HashSet、TreeSet、ArrayList、LinkedList、ArrayDeque、HashMap、TreeMap,这些都是线程不安全的集合类,但是它们的优点是性能好。如果需要使用线程安全的集合类,则可以使用Collections工具类提供的synchronizedXxx()方法,将这些集合类包装成线程安全的集合类。
java.util包下也有线程安全的集合类,例如Vector、Hashtable。这些集合类都是比较古老的API,虽然实现了线程安全,但是性能很差。所以即便是需要使用线程安全的集合类,也建议将线程不安全的集合类包装成线程安全集合类的方式,而不是直接使用这些古老的API。
从Java5开始,Java在java.util.concurrent包下提供了大量支持高效并发访问的集合类,它们既能包装良好的访问性能,有能包装线程安全。这些集合类可以分为两部分,它们的特征如下:
以Concurrent开头的集合类:
以Concurrent开头的集合类代表了支持并发访问的集合,它们可以支持多个线程并发写入访问,这些写入线程的所有操作都是线程安全的,但读取操作不必锁定。以Concurrent开头的集合类采用了更复杂的算法来保证永远不会锁住整个集合,因此在并发写入时有较好的性能。
以CopyOnWrite开头的集合类:
以CopyOnWrite开头的集合类采用复制底层数组的方式来实现写操作。当线程对此类集合执行读取操作时,线程将会直接读取集合本身,无须加锁与阻塞。当线程对此类集合执行写入操作时,集合会在底层复制一份新的数组,接下来对新的数组执行写入操作。由于对集合的写入操作都是对数组的副本执行操作,因此它是线程安全的。
扩展阅读
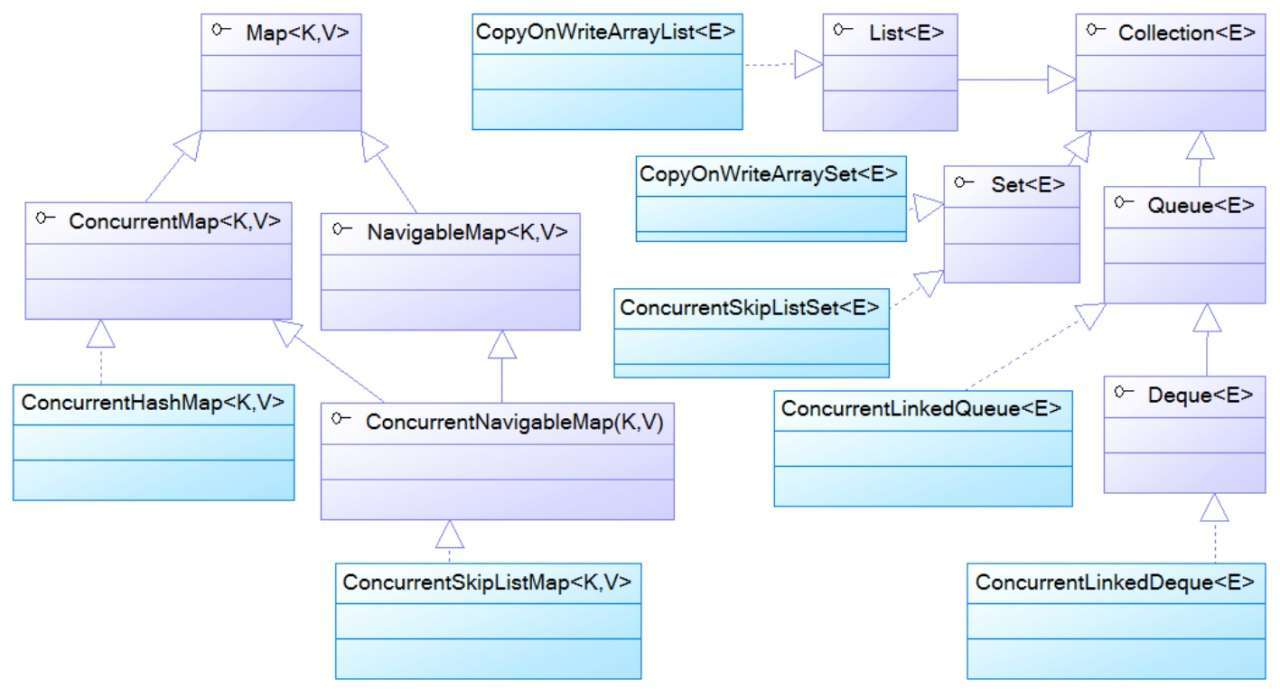
java.util.concurrent包下线程安全的集合类的体系结构:
✅ 如何得到一个线程安全的Map?
参考答案
- 使用Collections工具类,将线程不安全的Map包装成线程安全的Map;
- 使用java.util.concurrent包下的Map,如ConcurrentHashMap;
- 不建议使用Hashtable,虽然Hashtable是线程安全的,但是性能较差。
✅如何将集合变成线程安全的?
- 在调用集合前,使用synchronized或者ReentrantLock对代码加锁(读写都要加锁)
- 使用ThreadLocal,将集合放到线程内访问,但是这样集合中的值就不能被其他线程访问了
- 使用Collections.synchronizedXXX()方法,可以获得一个线程安全的集合
- 使用不可变集合进行封装,当集合是不可变的时候,自然是线程安全的
✅Java有哪些线程安全的集合?
Java1.5并发包(java.util.concurrent)包含线程安全集合类,允许在迭代时修改集合。 Java并发集合类主要包含以下几种:
ConcurrentHashMapConcurrentLinkedDequeConcurrentLinkedQueueConcurrentSkipListMapConcurrentSkipSetCopyOnWriteArrayListCopyOnWriteArraySet
✅ HashMap如何实现线程安全?
参考答案
- 直接使用
Hashtable类; - 直接使用
ConcurrentHashMap; - 使用
Collections将HashMap包装成线程安全的Map。
✅HashMap为什么线程不安全?
参考答案
HashMap在并发执行put操作时,可能会导致形成循环链表,从而引起死循环。
✅什么是COW,如何保证的线程安全?
Copy-On-Write简称COW,是一种用于程序设计中的优化策略。其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,才会真正把内容Copy出去形成一个新的内容然后再改,这是一种延时懒惰策略。 从JDK1.5开始Java并发包里提供了两个使用CopyOnWrite机制实现的并发容器,它们是CopyOnWriteArrayList和CopyOnWriteArraySet。CopyOnWrite容器非常有用,可以在非常多的并发场景中使用到。
CopyOnWriteArrayList相当于线程安全的ArrayList,CopyOnWriteArrayList使用了一种叫写时复制的方法,当有新元素add到CopyOnWriteArrayList时,先从原有的数组中拷贝一份出来,然后在新的数组做写操作,写完之后,再将原来的数组引用指向到新数组。
这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
注意:CopyOnWriteArrayList的整个add操作都是在锁的保护下进行的。也就是说add方法是线程安全的。 **CopyOnWrite并发容器用于读多写少的并发场景。**比如白名单,黑名单,商品类目的访问和更新场景。
和ArrayList不同的是,它具有以下特性:
- 支持高效率并发且是线程安全的
- 因为通常需要复制整个基础数组,所以可变操作(add()、set() 和 remove() 等等)的开销很大
- 迭代器支持hasNext(), next()等不可变操作,但不支持可变 remove()等操作
- 使用迭代器进行遍历的速度很快,并且不会与其他线程发生冲突。在构造迭代器时,迭代器依赖于不变的数组快照
✅HashMap、Hashtable和ConcurrentHashMap的区别?
参考答案
📚从线程安全角度:
HashMap是非线程安全的。Hashtable中的方法是同步的,所以它是线程安全的。ConcurrentHashMap在JDK 1.8之前使用分段锁保证线程安全,ConcurrentHashMap默认情况下将hash表分为16个桶(分片),在加锁的时候,针对每个单独的分片进行加锁,其他分片不受影响。锁的粒度更细,所以他的性能更好。ConcurrentHashMap在JDK 1.8中,采用了一种新的方式来实现线程安全,即使用了CAS+synchronized,这个实现被称为"分段锁"的变种,也被称为"锁分离",它将锁定粒度更细,把锁的粒度从整个Map降低到了单个桶。
📚从继承角度:
HashTable是基于陈旧的Dictionary类继承来的。HashMap继承的抽象类AbstractMap实现了Map接口。ConcurrentHashMap同样继承了抽象类AbstractMap,并且实现了ConcurrentMap。
📚从是否允许null值:
HashTable中,key和value都不允许出现null值,否则会抛出NullPointerException异常。HashMap中,null可以作为键或者值都可以。ConcurrentHashMap中,key和value都不允许为null。
📚默认初始容量和扩容机制:
HashMap的默认初始容量为16,默认的加载因子为0.75,即当HashMap中元素个数超过容量的75%时,会进行扩容操作。扩容时,容量会扩大为原来的两倍,并将原来的元素重新分配到新的桶中。Hashtable,默认初始容量为11,默认的加载因子为0.75,即当Hashtable中元素个数超过容量的75%时,会进行扩容操作。扩容时,容量会扩大为原来的两倍加1,并将原来的元素重新分配到新的桶中。ConcurrentHashMap,默认初始容量为16,默认的加载因子为0.75,即当ConcurrentHashMap中元素个数超过容量的75%时,会进行扩容操作。扩容时,容量会扩大为原来的两倍,并会采用分段锁机制,ConcurrentHashMap分为多个段(segment),每个段独立进行扩容操作,避免了整个ConcurrentHashMap的锁竞争。
📚遍历方式的内部实现上不同 :
- HashMap使用EntrySet进行遍历,即先获取到HashMap中所有的键值对(Entry),然后遍历Entry集合。支持fail-fast,也就是说在遍历过程中,若HashMap的结构被修改(添加或删除元素),则会抛
- ConcurrentModificationException。如果只需要遍历HashMap中的key或value,可以使用KeySet或Values来遍历。 Hashtable使用Enumeration进行遍历,即获取Hashtable中所有的key,然后遍历key集合。遍历过程中,Hashtable的结构发生变化时,Enumeration会失效。
- ConcurrentHashMap使用分段锁机制,因此在遍历时需要注意,遍历时ConcurrentHashMap的某个段被修改不会影响其他段的遍历。可以使用EntrySet、KeySet或Values来遍历ConcurrentHashMap,其中EntrySet遍历时效率最高。遍历过程中,ConcurrentHashMap的结构发生变化时,不会抛出ConcurrentModificationException异常,但是在遍历时可能会出现数据不一致的情况,因为遍历器仅提供了弱一致性保障。
| 特性/集合类 | HashMap | Hashtable | ConcurrentHashMap |
|---|---|---|---|
| 线程安全 | 否 | 是,基于方法锁 | 是,基于分段锁 |
| 继承关系 | AbstractMap | Dictionary | AbstractMap,ConcurrentMap |
| 允许null值 | K-V都允许 | K-V都不允许 | K-V都不允许 |
| 默认初始容量 | 16 | 11 | 16 |
| 默认加载因子 | 0.75 | 0.75 | 0.75 |
| 扩容后容量 | 原来两倍 | 原来两倍加1 | 原来两倍 |
| 是否支持fail-fast | 支持 | 不支持 | 支持fail-safe |
扩展阅读
从Hashtable的类名上就可以看出它是一个古老的类,它的命名甚至没有遵守Java的命名规范:每个单词的首字母都应该大写。也许当初开发Hashtable的工程师也没有注意到这一点,后来大量Java程序中使用了Hashtable类,所以这个类名也就不能改为HashTable了,否则将`导致大量程序需要改写。
与Vector类似的是,尽量少用Hashtable实现类,即使需要创建线程安全的Map实现类,也无须使用Hashtable实现类,可以通过Collections工具类把HashMap变成线程安全的Map。
✅介绍一下ConcurrentHashMap是怎么实现的?
参考答案
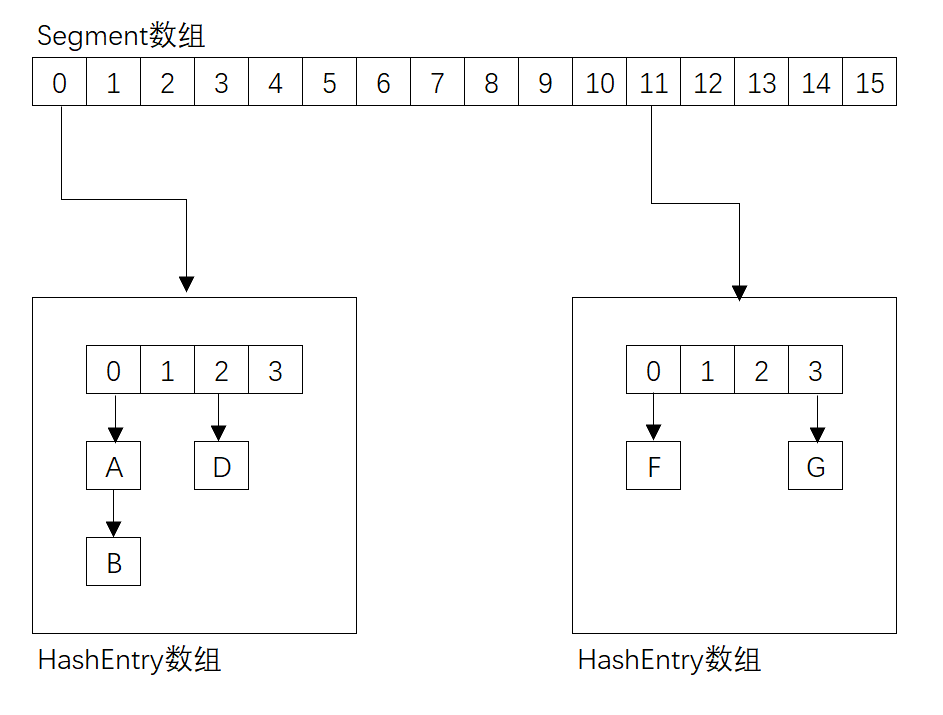
JDK 1.7中的实现:
在 jdk 1.7 中,ConcurrentHashMap 是由 Segment 数据结构和 HashEntry 数组结构构成,采取分段锁来保证安全性。Segment 是 ReentrantLock 重入锁,在 ConcurrentHashMap 中扮演锁的角色,HashEntry 则用于存储键值对数据。一个 ConcurrentHashMap 里包含一个 Segment 数组,一个 Segment 里包含一个 HashEntry 数组,Segment 的结构和 HashMap 类似,是一个数组和链表结构。
JDK 1.8中的实现:
JDK1.8 的实现已经摒弃了 Segment 的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 Synchronized 和 CAS 来操作,整个看起来就像是优化过且线程安全的 HashMap,虽然在 JDK1.8 中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本。
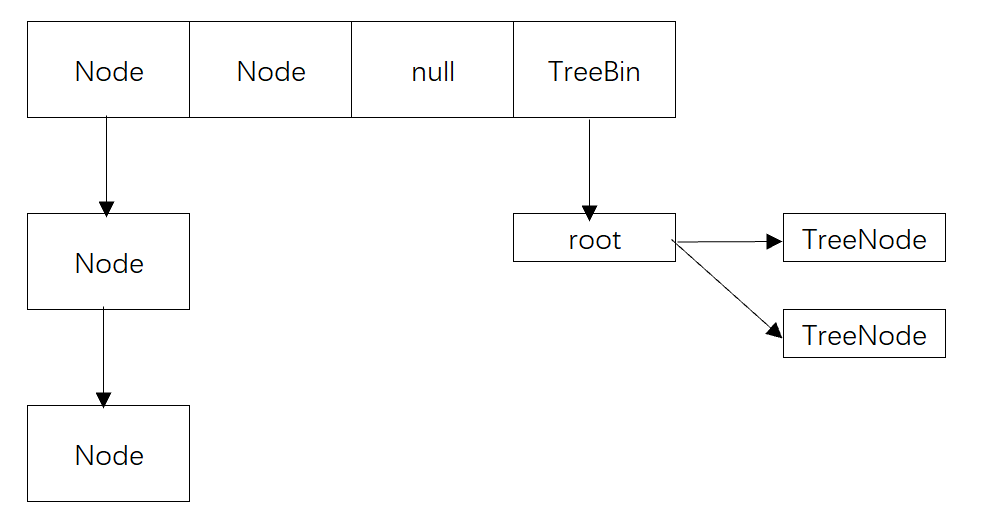
✅ConcurrentHashMap是如何保证线程安全的?
- 在JDK 1.7中,ConcurrentHashMap使用了分段锁技术,即将哈希表分成多个段,每个段拥有一个独立的锁。这样可以在多个线程同时访问哈希表时,只需要锁住需要操作的那个段,而不是整个哈希表,从而提高了并发性能。虽然JDK 1.7的这种方式可以减少锁竞争,但是在高并发场景下,仍然会出现锁竞争,从而导致性能下降。
- 在JDK 1.8中,ConcurrentHashMap的实现方式进行了改进,使用分段锁和“CAS+Synchronized”的机制来保证线程安全。在JDK 1.8中,ConcurrentHashMap会在添加或删除元素时,首先使用CAS操作来尝试修改元素,如果CAS操作失败,则使用Synchronized锁住当前槽,再次尝试put或者delete。这样可以避免分段锁机制下的锁粒度太大,以及在高并发场景下,由于线程数量过多导致的锁竞争问题,提高了并发性能。
源码分析
ConcurrentHashMap将哈希表分成多个段,每个段拥有一个独立的锁,这样可以在多个线程同时访问哈希表时,只需要锁住需要操作的那个段,而不是整个哈希表,从而提高了并发性能。下面是ConcurrentHashMap中分段锁的代码实现:
static final class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
// ...
}
static final class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
transient volatile HashEntry<K,V>[] table;
transient int count;
transient int modCount;
transient int threshold;
final float loadFactor;
}
在上面的代码中,我们可以看到,每个Segment都是ReentrantLock的实现,每个Segment包含一个HashEntry数组,每个HashEntry则包含一个key-value键值对。 接下来再看下在JDK 1.8中,ConcurrentHashMap使用了一种称为“CAS+Synchronized”的机制。在添加或删除元素时,首先使用CAS操作来尝试修改元素,如果CAS操作失败,则使用Synchronized锁住整个段,再次尝试修改元素。下面是ConcurrentHashMap中CAS+Synchronized机制的代码实现:
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
// 对 key 的 hashCode 进行扰动
int hash = spread(key.hashCode());
int binCount = 0;
// 循环操作
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果 table 为 null 或长度为 0,则进行初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 如果哈希槽为空,则通过 CAS 操作尝试插入新节点
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break;
}
// 如果哈希槽处已经有节点,且 hash 值为 MOVED,则说明正在进行扩容,需要帮助迁移数据
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
// 如果哈希槽处已经有节点,且 hash 值不为 MOVED,则进行链表/红黑树的节点遍历或插入操作
else {
V oldVal = null;
// 加锁,确保只有一个线程操作该节点的链表/红黑树
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
// 遍历链表,找到相同 key 的节点,更新值或插入新节点
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
// 将新节点插入到链表末尾
if (casNext(pred, new Node<K,V>(hash, key,
value, null))) {
break;
}
}
}
}
// 遍历红黑树,找到相同 key 的节点,更新值或插入新节点
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// 如果插入或更新成功,则进行可能的红黑树化操作
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
// 如果替换旧值成功,则返回旧值
if (oldVal != null)
return oldVal;
break;
}
}
}
//
在上述代码中,如果某个段为空,那么使用CAS操作来添加新节点;如果某个段中的第一个节点的hash值为MOVED,表示当前段正在进行扩容操作,那么就调用helpTransfer方法来协助扩容;否则,使用Synchronized锁住当前节点,然后进行节点的添加操作。
✅ConcurrentHashMap在哪些地方做了并发控制
对于JDK1.8来说,如果用一句话来讲的话,ConcurrentHashMap是通过synchnized和CAS自旋保证的线程安全,要想知道ConcurrentHashMap是如何加锁的,就要知道HashMap在哪些地方会导致线程安全问题,如初始化桶数组阶段和设置桶,插入链表,树化等阶段,都会有并发问题。 解决这些问题的前提,就要知道到底有多少线程在对map进行写入操作,这里ConcurrentHashMap通过sizeCtl变量完成,如果其为负数,则说明有多线程在操作,且Math.abs(sizeCtl)即为线程的数目。
初始化桶阶段
如果在此阶段不做并发控制,那么极有可能出现多个线程都去初始化桶的问题,导致内存浪费。所以Map在此处采用自旋操作和CAS操作,如果此时没有线程初始化,则去初始化,否则当前线程让出CPU时间片,等待下一次唤醒,源码如下:
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSetInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
// 省略
}
} finally {
sizeCtl = sc;
}
break;
}
}
put元素阶段
如果hash后发现桶中没有值,则会直接采用CAS插入并且返回 如果发现桶中有值,则对流程按照当前的桶节点为维度进行加锁,将值插入链表或者红黑树中,源码如下:
// 省略....
// 如果当前桶节点为null,直接CAS插入
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
// 省略....
// 如果桶节点不为空,则对当前桶进行加锁
else {
V oldVal = null;
synchronized (f) {
}
}
扩容阶段
多线程最大的好处就是可以充分利用CPU的核数,带来更高的性能,所以ConcurrentHashMap并没有一味的通过CAS或者锁去限制多线程,在扩容阶段,ConcurrentHashMap就通过多线程来加加速扩容。 在分析之前,我们需要知道两件事情:
- ConcurrentHashMap通过ForwardingNode来记录当前已经桶是否被迁移,如果oldTable[i] instanceOf ForwardingNode则说明处于i节点的桶已经被移动到newTable中了。它里面有一个变量nextTable,指向的是下一次扩容后的table
- transferIndex记录了当前扩容的桶索引,最开始为oldTable.length,它给下一个线程指定了要扩容的节点
得知到这两点后,我们可以梳理出如下扩容流程:
- 通过CPU核数为每个线程计算划分任务,每个线程最少的任务是迁移16个桶
- 将当前桶扩容的索引transferIndex赋值给当前线程,如果索引小于0,则说明扩容完毕,结束流程,否则
- 再将当前线程扩容后的索引赋值给transferIndex,譬如,如果transferIndex原来是32,那么赋值之后transferIndex应该变为16,这样下一个线程就可以从16开始扩容了。这里有一个小问题,如果两个线程同时拿到同一段范围之后,该怎么处理?答案是ConcurrentHashMap会通过CAS对transferIndex进行设置,只可能有一个成功,所以就不会存在上面的问题
- 之后就可以对真正的扩容流程进行加锁操作了
✅ConcurrentHashMap是如何保证fail-safe的
✅ConcurrentHashMap是怎么分段分组的?
参考答案
get操作:
Segment的get操作实现非常简单和高效,先经过一次再散列,然后使用这个散列值通过散列运算定位到 Segment,再通过散列算法定位到元素。get操作的高效之处在于整个get过程都不需要加锁,除非读到空的值才会加锁重读。原因就是将使用的共享变量定义成 volatile 类型。
put操作:
当执行put操作时,会经历两个步骤:
- 判断是否需要扩容;
- 定位到添加元素的位置,将其放入 HashEntry 数组中。
插入过程会进行第一次 key 的 hash 来定位 Segment 的位置,如果该 Segment 还没有初始化,即通过 CAS 操作进行赋值,然后进行第二次 hash 操作,找到相应的 HashEntry 的位置,这里会利用继承过来的锁的特性,在将数据插入指定的 HashEntry 位置时(尾插法),会通过继承 ReentrantLock 的 tryLock() 方法尝试去获取锁,如果获取成功就直接插入相应的位置,如果已经有线程获取该Segment的锁,那当前线程会以自旋的方式去继续的调用 tryLock() 方法去获取锁,超过指定次数就挂起,等待唤醒。
✅说一说你对LinkedHashMap的理解
参考答案
LinkedHashMap使用双向链表来维护key-value对的顺序(其实只需要考虑key的顺序),该链表负责维护Map的迭代顺序,迭代顺序与key-value对的插入顺序保持一致。
LinkedHashMap可以避免对HashMap、Hashtable里的key-value对进行排序(只要插入key-value对时保持顺序即可),同时又可避免使用TreeMap所增加的成本。
LinkedHashMap需要维护元素的插入顺序,因此性能略低于HashMap的性能。但因为它以链表来维护内部顺序,所以在迭代访问Map里的全部元素时将有较好的性能。
✅请介绍LinkedHashMap的底层原理
参考答案
LinkedHashMap继承于HashMap,它在HashMap的基础上,通过维护一条双向链表,解决了HashMap不能随时保持遍历顺序和插入顺序一致的问题。在实现上,LinkedHashMap很多方法直接继承自HashMap,仅为维护双向链表重写了部分方法。
如下图,淡蓝色的箭头表示前驱引用,红色箭头表示后继引用。每当有新的键值对节点插入时,新节点最终会接在tail引用指向的节点后面。而tail引用则会移动到新的节点上,这样一个双向链表就建立起来了。
✅ 请介绍TreeMap的底层原理
参考答案
TreeMap基于红黑树(Red-Black tree)实现。映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。TreeMap的基本操作containsKey、get、put、remove方法,它的时间复杂度是log(N)。
TreeMap包含几个重要的成员变量:root、size、comparator。其中root是红黑树的根节点。它是Entry类型,Entry是红黑树的节点,它包含了红黑树的6个基本组成:key、value、left、right、parent和color。Entry节点根据根据Key排序,包含的内容是value。Entry中key比较大小是根据比较器comparator来进行判断的。size是红黑树的节点个数。
🪟Set
✅Set是如何保证元素不重复的
在Java的Set体系中,根据实现方式不同主要分为两大类。HashSet和TreeSet。
TreeSet是二叉树实现的,TreeSet中的数据是自动排好序的,不允许放入null值;底层基于TreeMapHashSet是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束;底层基于HashMap
在HashSet中,基本的操作都是有HashMap底层实现的,因为HashSet底层是用HashMap存储数据的。当向HashSet中添加元素的时候,首先计算元素的hashCode值,然后通过扰动计算和按位与的方式计算出这个元素的存储位置,如果这个位置为空,就将元素添加进去;如果不为空,则用equals方法比较元素是否相等,相等就不添加,否则找一个空位添加。 TreeSet的底层是TreeMap的keySet(),而TreeMap是基于红黑树实现的,红黑树是一种平衡二叉查找树,它能保证任何一个节点的左右子树的高度差不会超过较矮的那棵的一倍。 TreeMap是按key排序的,元素在插入TreeSet时compareTo()方法要被调用,所以TreeSet中的元素要实现Comparable接口。TreeSet作为一种Set,它不允许出现重复元素。TreeSet是用compareTo()来判断重复元素的。
扩展阅读:
📚HashSet,TreeSet,LinkedHashSet,BitSet有何区别
- 功能不同:HashSet是功能最简单的Set,只提供去重的能力;LinkedHashSet不仅提供去重功能,而且还能记录插入和查询顺序;TreeSet提供了去重和排序的能力;BitSet不仅能提供去重能力,同时也能减少存储空间的浪费,不过对于普通的对象不太友好,需要做额外处理
- 实现方式不同:HashSet基于HashMap,去重是根据HashCode和equals方法的;LinkedHashSet是基于LinkedHashMap,通过双向链表记录插入顺序;TreeSet是基于TreeMap的,去重是根据compareTo方法的;BitSet基于位数组,一般只用于数字的存储和去重
- 其实BitSet只是叫做Set而已,它既没有实现Collection接口,也和Iterable接口没有什么关系,但是是名字相似而已
📚什么是BitSet?有什么作用?
顾名思义,BitSet是位集合,通常来说,位集合的底层的数据结构是一个bit数组,如果第n位为1,则表明数字n在该数组中。 举个例子,如果调用BitSet#set(10),业务语意是把10放到BitSet中,内部的操作则是通过把二进制的第十位(低位)置为1。这样,就代表BitSet中包含了10这个数字。 不过,对于Java中的BitSet来讲,因为Java不知道bit类型,所以它的底层结构并不是一个bit类型数组,但是也不是一个byte类型数组,而是一个long类型的数组,这样设置的目的是因为long有64位,每次可以读取64位,在进行set或者or操作的时候,for循环的次数会更少,提高了性能。 它最大的好处就是对于多个数字来说,降低了存储空间,如正常情况下,将每一个int类型(32bit)的数字存储到内存中需要 4B * (2^31-1) = 256 MB,但是如果用BitSet的话,就会节省到原来的1/32。 BitSet常见的使用例子往往和大数相关:
- 现在有1千万个随机数,随机数的范围在1到1亿之间。求出将1到1亿之间没有在随机数中的数
- 统计N亿个数据中没有出现的数据
- 将N亿个不同数据进行排序等
但是BitSet也有缺点,譬如集合中存储一些差值比较大的数,如1亿和1两个数,就会导致内存的严重浪费
✅Map和Set有什么区别?
参考答案
Set代表无序的,元素不可重复的集合;
Map代表具有映射关系(key-value)的集合,其所有的key是一个Set集合,即key无序且不能重复。
✅说一说TreeSet和HashSet的区别
参考答案
HashSet、TreeSet中的元素都是不能重复的,并且它们都是线程不安全的,二者的区别是:
- HashSet中的元素可以是null,但TreeSet中的元素不能是null;
- HashSet不能保证元素的排列顺序,而TreeSet支持自然排序、定制排序两种排序的方式;
- HashSet底层是采用哈希表实现的,而TreeSet底层是采用红黑树实现的。
✅说一说HashSet的底层结构
参考答案
HashSet是基于HashMap实现的,默认构造函数是构建一个初始容量为16,负载因子为0.75 的HashMap。它封装了一个 HashMap 对象来存储所有的集合元素,所有放入 HashSet 中的集合元素实际上由 HashMap 的 key 来保存,而 HashMap 的 value 则存储了一个 PRESENT,它是一个静态的 Object 对象。
🪟List
✅List和Set有什么区别?
参考答案
Set代表无序的,元素不可重复的集合。
List代表有序的,元素可以重复的集合。
✅你能说出几种集合的排序方式?
当问到集合排序,第一时间想到List,因为Set集合无序不重复,Map集合是K/V键值对存储。Java.util包中的List接口继承了Collection接口,所以对这些对象进行排序的时候,要么让对象类自己实现同类对象的比较,要么借助比较器进行比较排序。 举例:学生实体类,包含姓名和年龄属性,比较时先按姓名升序排序,如果姓名相同则按年龄升序排序。
📚第一种:实体类自己实现Comparable接口比较
public class Student implements Comparable<Student>{
private String name;
private int age;
@Override
public int compareTo(Student o) {
int flag = this.name.compareTo(o.name);
if(flag == 0) {
flag = this.age - o.age;
}
return flag;
}
}
Collections.sort(students);
📚第二种:借助比较器进行排序
public class Student {
private String name;
private int age;
}
Collections.sort(students, (o1, o2) -> {
int flag = o1.getName().compareTo(o2.getName());
if(flag == 0) {
flag = o1.getAge() - o2.getAge();
}
return flag;
});
📚第三种:借助Stream进行排序,借助Stream的API,底层还是通过Comparable实现的
public class Student {
private String name;
private int age;
}
// 如果Student实现了Comparable
students.stream().sorted().collect(Collectors.toList());
// 如果Student没有实现Comparable
students.stream().sorted((o1, o2) -> {
int flag = o1.getName().compareTo(o2.getName());
if(flag == 0) {
flag = o1.getAge() - o2.getAge();
}
return flag;
}).collect(Collectors.toList());
扩展阅读
📚有了Comparable为什么还需要Comparator?
Comparable用于使某个类具备可排序能力。如之前的Student类,实现该接口后覆盖其compareTo方法,即可具备可排序的能力。 但是仍然存在一些二方库的类没有实现Comparable,但是调用方也需要比较的,此时就需要使用Comparator接口。 Comparator是一个比较器接口,可以用来给不具备排序能力的对象进行排序。如上述代码中对不具备排序能力的Student进行排序。
📚compareTo和equals的使用场景有何区别?
compareTo常用于排序和BigDecimal等数值的比较。 equals则是常用于业务语义中两个对象是否相同,如String常常通过equals来比较是否字面意义相同。
📚既然Set是无序的,还怎么排序?
这里说的是两个语境的不同,Set的无序,指的是插入顺序是无序的。虽然Set的插入顺序是无序的,Set也可以基于SortedSet要求对象实现Comparable来对Set中的元素进行排序。
📚Set的实现类都是插入无序的吗?
不是,Set有一个实现类是LinkedHashSet,它引用了LinkedHashMap,通过双向链表记录了每个node的插入顺序和查询顺序(可选),以此来达到Set的插入有序性。
✅ArrayList、LinkedList与Vector的区别?
参考答案
首先都实现了List 接口,使用方式也很相似,主要区别在于实现方式的不同,对不同的操作具有不同的效率。
ArrayList是一个可改变大小的数组。当更多的元素加入到ArrayList中时,其大小将会动态地增长,内部的元素可以直接通过get与set方法进行访问,因为ArrayList本质上就是一个数组。LinkedList是一个双向链表。在添加和删除元素时具有比ArrayList更好的性能,但在get与set方面弱于ArrayList。当然这些对比都是指数据量很大或者操作很频繁的情况下的对比,如果数据和运算量很小,那么对比将失去意义。Vector和ArrayList类似,但属于强同步类。如果你的程序本身是线程安全的(thread-safe,没有在多个线程之间共享同一个./集合/对象),那么使用ArrayList是更好的选择。
所以它们的区别是:
- 对于随机访问
ArrayList要优于LinkedList,ArrayList可以根据下标以O(1)时间复杂度对元素进行随机访问,而LinkedList的每一个元素都依靠地址指针和它后一个元素连接在一起,查找某个元素的时间复杂度是O(N); - 对于插入和删除操作,
LinkedList要优于ArrayList,因为当元素被添加到LinkedList任意位置的时候,不需要像ArrayList那样重新计算大小或者是更新索引; LinkedList比ArrayList更占内存,因为LinkedList的节点除了存储数据,还存储了两个引用,一个指向前一个元素,一个指向后一个元素。Vector和ArrayList在更多元素添加进来时会请求更大的空间。Vector每次请求其大小的双倍空间,而ArrayList每次对size增长50%。
✅介绍一下ArrayList的数据结构?
参考答案
ArrayList的底层是用数组来实现的,默认第一次插入元素时创建大小为10的数组,超出限制时会增加50%的容量,并且数据以 System.arraycopy() 复制到新的数组,因此最好能给出数组大小的预估值。
按数组下标访问元素的性能很高,这是数组的基本优势。直接在数组末尾加入元素的性能也高,但如果按下标插入、删除元素,则要用 System.arraycopy() 来移动部分受影响的元素,性能就变差了,这是基本劣势。
✅ArrayList是如何扩容的?
首先,我们要知道ArrayList是基于数组的,在申请数组的时候,只能申请一个定长的数组,那么List是如何通过数组扩容的呢?ArrayList的扩容分为以下几步:
- 检查新增元素后是否会超过数组的容量,如果超过,则进行下一步扩容。
- 设置新的容量为老容量的
1.5倍,最多不超过2^31-1。 - 之后,申请一个容量为1.5倍的数组,并将老数组的元素复制到新数组中,扩容完成。
Java 8中ArrayList的容量最大是Integer.MAX_VALUE - 8,即2^31-9。这是由于在Java 8中,ArrayList内部实现进行了一些改进,使用了一些数组复制的技巧来提高性能和内存利用率,而这些技巧需要额外的8个元素的空间来进行优化。
✅ArrayList的序列化是怎么实现的?
ArrayList类的序列化是通过Java的序列化机制实现的。Java的序列化机制允许将一个对象转换为字节序列,以便可以在网络上传输或者存储到文件系统中。
在序列化过程中,如果被序列化的类中定义了writeObject 和 readObject 方法,虚拟机会试图调用对象类里的 writeObject 和 readObject 方法,进行用户自定义的序列化和反序列化。 如果没有这样的方法,则默认调用是 ObjectOutputStream 的 defaultWriteObject 方法以及 ObjectInputStream 的 defaultReadObject 方法。 用户自定义的 writeObject 和 readObject 方法可以允许用户控制序列化的过程,比如可以在序列化的过程中动态改变序列化的数值。
ArrayList底层是通过Object数组完成数据存储的,但是这个数组被声明成了 transient,说明在默认的序列化策略中并没有序列化数组字段。
ArrayList重写了writeObject和readObject方法,如下所示:
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
✅有哪些线程安全的List?
参考答案
Vector
Vector是比较古老的API,虽然保证了线程安全,但是由于效率低一般不建议使用。Collections.SynchronizedList
SynchronizedList是Collections的内部类,Collections提供了synchronizedList方法,可以将一个线程不安全的List包装成线程安全的List,即SynchronizedList。它比Vector有更好的扩展性和兼容性,但是它所有的方法都带有同步锁,也不是性能最优的List。CopyOnWriteArrayList
CopyOnWriteArrayList是Java 1.5在java.util.concurrent包下增加的类,它采用复制底层数组的方式来实现写操作。当线程对此类集合执行读取操作时,线程将会直接读取集合本身,无须加锁与阻塞。当线程对此类集合执行写入操作时,集合会在底层复制一份新的数组,接下来对新的数组执行写入操作。由于对集合的写入操作都是对数组的副本执行操作,因此它是线程安全的。在所有线程安全的List中,它是性能最优的方案。
✅谈谈CopyOnWriteArrayList的原理
参考答案
CopyOnWriteArrayList是Java并发包里提供的并发类,简单来说它就是一个线程安全且读操作无锁的ArrayList。正如其名字一样,在写操作时会复制一份新的List,在新的List上完成写操作,然后再将原引用指向新的List。这样就保证了写操作的线程安全。
CopyOnWriteArrayList允许线程并发访问读操作,这个时候是没有加锁限制的,性能较高。而写操作的时候,则首先将容器复制一份,然后在新的副本上执行写操作,这个时候写操作是上锁的。结束之后再将原容器的引用指向新容器。注意,在上锁执行写操作的过程中,如果有需要读操作,会作用在原容器上。因此上锁的写操作不会影响到并发访问的读操作。
- 优点:读操作性能很高,因为无需任何同步措施,比较适用于读多写少的并发场景。在遍历传统的List时,若中途有别的线程对其进行修改,则会抛出ConcurrentModificationException异常。而CopyOnWriteArrayList由于其"读写分离"的思想,遍历和修改操作分别作用在不同的List容器,所以在使用迭代器进行遍历时候,也就不会抛出ConcurrentModificationException异常了。
- 缺点:一是内存占用问题,毕竟每次执行写操作都要将原容器拷贝一份,数据量大时,对内存压力较大,可能会引起频繁GC。二是无法保证实时性,Vector对于读写操作均加锁同步,可以保证读和写的强一致性。而CopyOnWriteArrayList由于其实现策略的原因,写和读分别作用在新老不同容器上,在写操作执行过程中,读不会阻塞但读取到的却是老容器的数据。
✅什么是fail-fast?什么是fail-safe?
Fail-fast是指当程序发生错误时,快速失败并终止程序执行的一种错误检测机制。在Java中,Fail-fast机制常用于集合类的错误检测。当使用迭代器遍历一个集合对象时,如果在对集合对象进行修改(增加、删除、修改)时,会抛出Concurrent Modification Exception(并发修改异常),这就是Fail-fast机制的作用。Fail-safe则是指当程序发生错误时,能够安全地失败,不会对程序造成进一步的损害。采用安全失败机制的集合容器在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。这样,即使在遍历过程中集合内容发生了变化,也不会影响原始集合,从而保证了程序的安全性。
在系统设计中,快速失效(fail-fast)系统一种可以立即报告任何可能表明故障的情况的系统。快速失效系统通常设计用于停止正常操作,而不是试图继续可能存在缺陷的过程。其实,这是一种理念,说白了就是在做系统设计的时候先考虑异常情况,一旦发生异常,直接停止并上报。 举一个最简单的fail-fast的例子:
public int divide(int dividend,int divisor){
if(divisor == 0){
throw new RuntimeException("divisor can't be zero");
}
return dividend/divisor;
}
上面的代码是一个对两个整数做除法的方法,在divide方法中,我们对被除数做了个简单的检查,如果其值为0,那么就直接抛出一个异常,并明确提示异常原因。这其实就是fail-fast理念的实际应用。
- 在Java中,集合类中有用到fail-fast机制进行设计,一旦使用不当,触发fail-fast机制设计的代码,就会发生非预期情况。在集合类中,为了避免并发修改,会维护一个
expectedModCount属性,他表示这个迭代器预期该集合被修改的次数。还有一个modCount属性,他表示该集合实际被修改的次数。在集合被修改时,会去比较modCount和expectedModCount的值,如果不一致,则会触发fail-fast机制,抛出ConcurrentModificationException(并发修改异常)。 - fail-safe 机制是为线程安全的集合准备的,可以避免像 fail-fast 一样在并发使用集合的时候,不断地抛出异常。
扩展阅读
📚fail-fast在集合中如何被触发的?
我们通常说的Java中的fail-fast机制,默认指的是Java集合的一种错误检测机制。当多个线程对部分集合进行结构上的改变的操作时,有可能会产生fail-fast机制,这个时候就会抛出ConcurrentModificationException(并发修改异常)。 在Java中, 如果在foreach 循环里对某些集合元素进行元素的 remove/add 操作的时候,就会触发fail-fast机制,进而抛出ConcurrentModificationException。 如以下代码:
List<String> userNames = new ArrayList<String>() {{
add("Hollis");
add("hollis");
add("HollisChuang");
add("H");
}};
for (String userName : userNames) {
if (userName.equals("Hollis")) {
userNames.remove(userName);
}
}
System.out.println(userNames)
以上代码,使用增强for循环遍历元素,并尝试删除其中的Hollis字符串元素。运行以上代码,会抛出以下异常:
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:909)
at java.util.ArrayList$Itr.next(ArrayList.java:859)
at com.hollis.ForEach.main(ForEach.java:22)
同样的,在增强for循环中使用add方法添加元素,结果也会同样抛出该异常。 在深入原理之前,我们先尝试把foreach进行解语法,看一下foreach具体如何实现的。 我们使用jad工具,对编译后的class进行反编译,得到以下代码:
public static void main(String[] args) {
// 使用ImmutableList初始化一个List
List<String> userNames = new ArrayList<String>() {{
add("Hollis");
add("hollis");
add("HollisChuang");
add("H");
}};
Iterator iterator = userNames.iterator();
do
{
if(!iterator.hasNext())
break;
String userName = (String)iterator.next();
if(userName.equals("Hollis"))
userNames.remove(userName);
} while(true);
System.out.println(userNames);
}
可以发现,foreach其实是依赖了while循环和Iterator实现的。
📚抛出并发修改异常的真正原因又是什么呢?
通过以上代码的异常堆栈,我们可以跟踪到真正抛出异常的代码是:
java.util.ArrayList$Itr.checkForComodification(ArrayList.java:909)
该方法是在iterator.next()方法中调用的。我们看下该方法的实现:
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
如上,在该方法中对modCount和expectedModCount进行了比较,如果二者不相等,则抛出ConcurrentModificationException。 那么,modCount和expectedModCount是什么?是什么原因导致他们的值不相等的呢? modCount是ArrayList中的一个成员变量。它表示该集合实际被修改的次数。
List<String> userNames = new ArrayList<String>() {{
add("Hollis");
add("hollis");
add("HollisChuang");
add("H");
}};
当使用以上代码初始化集合之后该变量就有了。初始值为0。
expectedModCount 是 ArrayList中的一个内部类——Itr中的成员变量。
Iterator iterator = userNames.iterator();
以上代码,即可得到一个 Itr类,该类实现了Iterator接口。 expectedModCount表示这个迭代器预期该集合被修改的次数。其值随着Itr被创建而初始化。只有通过迭代器对集合进行操作,该值才会改变。 那么,接着我们看下userNames.remove(userName);方法里面做了什么事情,为什么会导致expectedModCount和modCount的值不一样。 通过翻阅代码,我们也可以发现,remove方法核心逻辑如下:
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
可以看到,它只修改了modCount,并没有对expectedModCount做任何操作。 简单画一张图描述下以上场景:
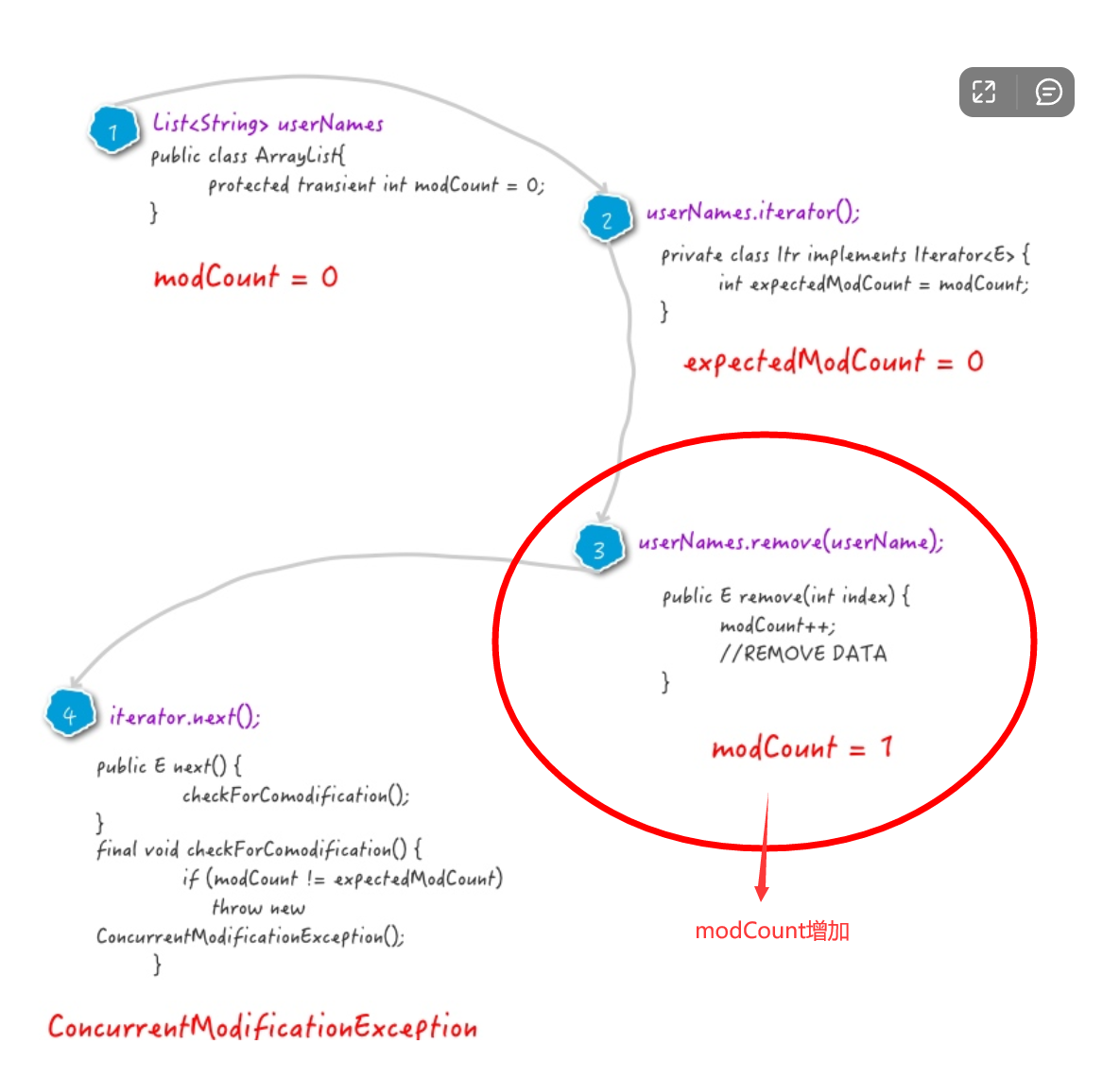
从这个图我们可以清晰看到调用删除remove方法时modCount++1,使得modCount != expectedModCount,从而抛出异常throw new ConcurrentModificationException();。
简单总结一下,之所以会抛出并发修改异常,是因为我们的代码中使用了增强for循环,而在增强for循环中,集合遍历是通过iterator进行的,但是元素的add/remove却是直接使用的集合类自己的方法。这就导致iterator在遍历的时候,会发现有一个元素在自己不知不觉的情况下就被删除/添加了,就会抛出一个异常,用来提示用户,可能发生了并发修改! 所以,在使用Java的集合类的时候,如果发生ConcurrentModificationException,优先考虑fail-fast有关的情况,实际上这里并没有真的发生并发,只是Iterator使用了fail-fast的保护机制,只要他发现有某一次修改是未经过自己进行的,那么就会抛出异常。
📚如何避免触发fail-fast机制?
为了避免触发fail-fast机制,导致异常,我们可以使用Java中提供的一些采用了fail-safe机制的集合类。 这样的集合容器在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。 java.util.concurrent包下的容器都是fail-safe的,可以在多线程下并发使用,并发修改。同时也可以在foreach中进行add/remove 。 我们拿CopyOnWriteArrayList这个fail-safe的集合类来简单分析一下。
public static void main(String[] args) {
List<String> userNames = new CopyOnWriteArrayList<String>() {{
add("Hollis");
add("hollis");
add("HollisChuang");
add("H");
}};
userNames.iterator();
for (String userName : userNames) {
if (userName.equals("Hollis")) {
userNames.remove(userName);
}
}
System.out.println(userNames);
}
以上代码,使用CopyOnWriteArrayList代替了ArrayList,就不会发生异常。 fail-safe集合的所有对集合的修改都是先拷贝一份副本,然后在副本集合上进行的,并不是直接对原集合进行修改。并且这些修改方法,如add/remove都是通过加锁来控制并发的。 所以,CopyOnWriteArrayList中的迭代器在迭代的过程中不需要做fail-fast的并发检测。(因为fail-fast的主要目的就是识别并发,然后通过异常的方式通知用户) 但是,虽然基于拷贝内容的优点是避免了ConcurrentModificationException,但同样地,迭代器并不能访问到修改后的内容。如以下代码:
public static void main(String[] args) {
List<String> userNames = new CopyOnWriteArrayList<String>() {{
add("Hollis");
add("hollis");
add("HollisChuang");
add("H");
}};
Iterator it = userNames.iterator();
for (String userName : userNames) {
if (userName.equals("Hollis")) {
userNames.remove(userName);
}
}
System.out.println(userNames);
while(it.hasNext()){
System.out.println(it.next());
}
}
我们得到CopyOnWriteArrayList的Iterator之后,通过for循环直接删除原数组中的值,最后在结尾处输出Iterator,结果发现内容如下:
[hollis, HollisChuang, H]
Hollis
hollis
HollisChuang
H
迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的。
📚什么是Copy-On-Write?
在了解了CopyOnWriteArrayList之后,不知道大家会不会有这样的疑问:他的add/remove等方法都已经加锁了,还要copy一份再修改干嘛?多此一举?同样是线程安全的集合,这玩意和Vector有啥区别呢? Copy-On-Write简称COW,是一种用于程序设计中的优化策略。其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,才会真正把内容Copy出去形成一个新的内容然后再改,这是一种延时懒惰策略。 CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。 CopyOnWriteArrayList中add/remove等写方法是需要加锁的,目的是为了避免Copy出N个副本出来,导致并发写。 但是,CopyOnWriteArrayList中的读方法是没有加锁的。
public E get(int index) {
return get(getArray(), index);
}
这样做的好处是我们可以对CopyOnWrite容器进行并发的读,当然,这里读到的数据可能不是最新的。因为写时复制的思想是通过延时更新的策略来实现数据的最终一致性的,并非强一致性。 所以CopyOnWrite容器是一种读写分离的思想,读和写不同的容器。而Vector在读写的时候使用同一个容器,读写互斥,同时只能做一件事儿。
✅遍历的同时修改一个List有几种方式?
我们知道,在foreach的同时修改集合,会触发fail-fast机制,要避免fail-fast机制,有如下处理方案:
- 通过普通的for循环
public void listRemove() {
List<Student> students = this.getStudents();
for (int i=0; i<students.size(); i++) {
if (students.get(i).getId()%3 == 0) {
Student student = students.get(i);
students.remove(student);
//做一次i--,避免漏删
i--;
}
}
}
- 使用迭代器循环
public void iteratorRemove() {
List<Student> students = this.getStudents();
Iterator<Student> stuIter = students.iterator();
while (stuIter.hasNext()) {
Student student = stuIter.next();
if (student.getId() % 2 == 0) {
//这里要使用Iterator的remove方法移除当前对象,如果使用List的remove方法,则同样会出现ConcurrentModificationException
stuIter.remove();
}
}
}
- 将原来的
copy一份副本,遍历原来的list,然后删除副本(fail-safe)
public void copyRemove() {
// 注意,这种方法的equals需要重写
List<Student> students = this.getStudents();
List<Student> studentsCopy = deepclone(students);
for(Student stu : students) {
if(needDel(stu)) {
studentsCopy.remove(stu);
}
}
}
- 使用并发安全的集合类
public void cowRemove() {
List<String> students = new CopyOnWriteArrayList<>(this.getStudents());
for(Student stu : students) {
if(needDel(stu)) {
students.remove(stu);
}
}
}
- 通过
Stream的过滤方法,因为Stream每次处理后都会生成一个新的Stream,不存在并发问题,所以Stream的filter也可以修改list集合
public List<String> streamRemove() {
List<String> students = this.getStudents();
return students.stream()
.filter(this::needDel)
.collect(Collectors.toList());
}
✅Stream(不是IOStream)有哪些方法?
参考答案
Stream提供了大量的方法进行聚集操作,这些方法既可以是“中间的”,也可以是“末端的”。
- 中间方法:中间操作允许流保持打开状态,并允许直接调用后续方法。上面程序中的map()方法就是中间方法。中间方法的返回值是另外一个流。
- 末端方法:末端方法是对流的最终操作。当对某个Stream执行末端方法后,该流将会被“消耗”且不再可用。上面程序中的sum()、count()、average()等方法都是末端方法。
除此之外,关于流的方法还有如下两个特征:
- 有状态的方法:这种方法会给流增加一些新的属性,比如元素的唯一性、元素的最大数量、保证元素以排序的方式被处理等。有状态的方法往往需要更大的性能开销。
- 短路方法:短路方法可以尽早结束对流的操作,不必检查所有的元素。
下面简单介绍一下Stream常用的中间方法:
- filter(Predicate predicate):过滤Stream中所有不符合predicate的元素。
- mapToXxx(ToXxxFunction mapper):使用ToXxxFunction对流中的元素执行一对一的转换,该方法返回的新流中包含了ToXxxFunction转换生成的所有元素。
- peek(Consumer action):依次对每个元素执行一些操作,该方法返回的流与原有流包含相同的元素。该方法主要用于调试。
- distinct():该方法用于排序流中所有重复的元素(判断元素重复的标准是使用equals()比较返回true)。这是一个有状态的方法。
- sorted():该方法用于保证流中的元素在后续的访问中处于有序状态。这是一个有状态的方法。
- limit(long maxSize):该方法用于保证对该流的后续访问中最大允许访问的元素个数。这是一个有状态的、短路方法。
下面简单介绍一下Stream常用的末端方法:
- forEach(Consumer action):遍历流中所有元素,对每个元素执行action。
- toArray():将流中所有元素转换为一个数组。
- reduce():该方法有三个重载的版本,都用于通过某种操作来合并流中的元素。
- min():返回流中所有元素的最小值。
- max():返回流中所有元素的最大值。
- count():返回流中所有元素的数量。
- anyMatch(Predicate predicate):判断流中是否至少包含一个元素符合Predicate条件。
- noneMatch(Predicate predicate):判断流中是否所有元素都不符合Predicate条件。
- findFirst():返回流中的第一个元素。
- findAny():返回流中的任意一个元素。
除此之外,Java 8允许使用流式API来操作集合,Collection接口提供了一个stream()默认方法,该方法可返回该集合对应的流,接下来即可通过流式API来操作集合元素。由于Stream可以对集合元素进行整体的聚集操作,因此Stream极大地丰富了集合的功能。
扩展阅读
Java 8新增了Stream、IntStream、LongStream、DoubleStream等流式API,这些API代表多个支持串行和并行聚集操作的元素。上面4个接口中,Stream是一个通用的流接口,而IntStream、LongStream、DoubleStream则代表元素类型为int、long、double的流。
Java 8还为上面每个流式API提供了对应的Builder,例如Stream.Builder、IntStream.Builder、LongStream.Builder、DoubleStream.Builder,开发者可以通过这些Builder来创建对应的流。
独立使用Stream的步骤如下:
- 使用Stream或XxxStream的builder()类方法创建该Stream对应的Builder。
- 重复调用Builder的add()方法向该流中添加多个元素。
- 调用Builder的build()方法获取对应的Stream。
- 调用Stream的聚集方法。
在上面4个步骤中,第4步可以根据具体需求来调用不同的方法,Stream提供了大量的聚集方法供用户调用,具体可参考Stream或XxxStream的API文档。对于大部分聚集方法而言,每个Stream只能执行一次。
✅如何利用List实现LRU?
LRU,即最近最少使用策略,基于时空局部性原理(最近访问的,未来也会被访问),往往作为缓存淘汰的策略,如Redis和GuavaMap都使用了这种淘汰策略。 我们可以基于LinkedList来实现LRU,因为LinkedList基于双向链表,每个结点都会记录上一个和下一个的节点,具体实现方式如下:
public class LruListCache<E> {
private final int maxSize;
private final LinkedList<E> list = new LinkedList<>();
public LruListCache(int maxSize) {
this.maxSize = maxSize;
}
public void add(E e) {
if (list.size() < maxSize) {
list.addFirst(e);
} else {
list.removeLast();
list.addFirst(e);
}
}
public E get(int index) {
E e = list.get(index);
list.remove(e);
add(e);
return e;
}
@Override
public String toString() {
return list.toString();
}
}
🪟Queue
✅ BlockingQueue中有哪些方法,为什么这样设计?
参考答案
为了应对不同的业务场景,BlockingQueue 提供了4 组不同的方法用于插入、移除以及对队列中的元素进行检查。如果请求的操作不能得到立即执行的话,每组方法的表现是不同的。这些方法如下:
| 抛异常 | 特定值 | 阻塞 | 超时 | |
|---|---|---|---|---|
| 插入 | add(e) | offer(e) | put(e) | offer(e, time, unit) |
| 移除 | remove() | poll() | take() | poll(time, unit) |
| 检查 | element() | peek() |
四组不同的行为方式含义如下:
- 抛异常:如果操作无法立即执行,则抛一个异常;
- 特定值:如果操作无法立即执行,则返回一个特定的值(一般是 true / false)。
- 阻塞:如果操作无法立即执行,则该方法调用将会发生阻塞,直到能够执行;
- 超时:如果操作无法立即执行,则该方法调用将会发生阻塞,直到能够执行。但等待时间不会超过给定值,并返回一个特定值以告知该操作是否成功(典型的是true / false)。
✅BlockingQueue是怎么实现的?
参考答案
BlockingQueue是一个接口,它的实现类有ArrayBlockingQueue、DelayQueue、 LinkedBlockingQueue、PriorityBlockingQueue、SynchronousQueue等。它们的区别主要体现在存储结构上或对元素操作上的不同,但是对于put与take操作的原理是类似的。下面以ArrayBlockingQueue为例,来说明BlockingQueue的实现原理。
首先看一下ArrayBlockingQueue的构造函数,它初始化了put和take函数中用到的关键成员变量,这两个变量的类型分别是ReentrantLock和Condition。ReentrantLock是AbstractQueuedSynchronizer(AQS)的子类,它的newCondition函数返回的Condition实例,是定义在AQS类内部的ConditionObject类,该类可以直接调用AQS相关的函数。
public ArrayBlockingQueue(int capacity, boolean fair) { if (capacity <= 0) throw new IllegalArgumentException(); this.items = new Object[capacity]; lock = new ReentrantLock(fair); notEmpty = lock.newCondition(); notFull = lock.newCondition(); }
put函数会在队列末尾添加元素,如果队列已经满了,无法添加元素的话,就一直阻塞等待到可以加入为止。函数的源码如下所示。我们会发现put函数使用了wait/notify的机制。与一般生产者-消费者的实现方式不同,同步队列使用ReentrantLock和Condition相结合的机制,即先获得锁,再等待,而不是synchronized和wait的机制。
public void put(E e) throws InterruptedException { checkNotNull(e); final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { while (count == items.length) notFull.await(); enqueue(e); } finally { lock.unlock(); } }
再来看一下消费者调用的take函数,take函数在队列为空时会被阻塞,一直到阻塞队列加入了新的元素。
public E take() throws InterruptedException { final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { while (count == 0) notEmpty.await(); return dequeue(); } finally { lock.unlock(); } }
扩展阅读
await操作:
我们发现ArrayBlockingQueue并没有使用Object.wait,而是使用的Condition.await,这是为什么呢?Condition对象可以提供和Object的wait和notify一样的行为,但是后者必须先获取synchronized这个内置的monitor锁才能调用,而Condition则必须先获取ReentrantLock。这两种方式在阻塞等待时都会将相应的锁释放掉,但是Condition的等待可以中断,这是二者唯一的区别。
我们先来看一下Condition的await函数,await函数的流程大致如下图所示。await函数主要有三个步骤,一是调用addConditionWaiter函数,在condition wait queue队列中添加一个节点,代表当前线程在等待一个消息。然后调用fullyRelease函数,将持有的锁释放掉,调用的是AQS的函数。最后一直调用isOnSyncQueue函数判断节点是否被转移到sync queue队列上,也就是AQS中等待获取锁的队列。如果没有,则进入阻塞状态,如果已经在队列上,则调用acquireQueued函数重新获取锁。
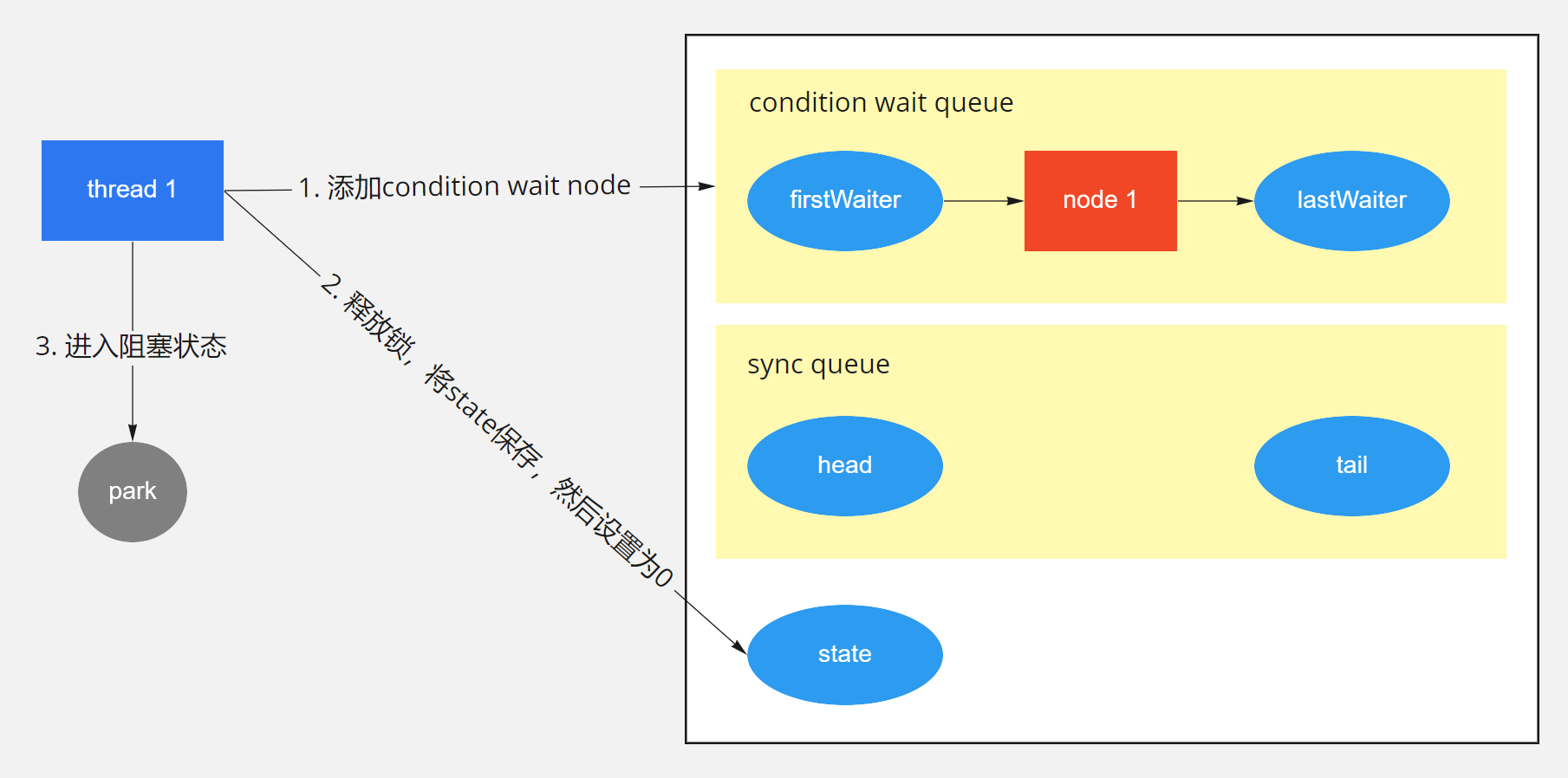
signal操作:
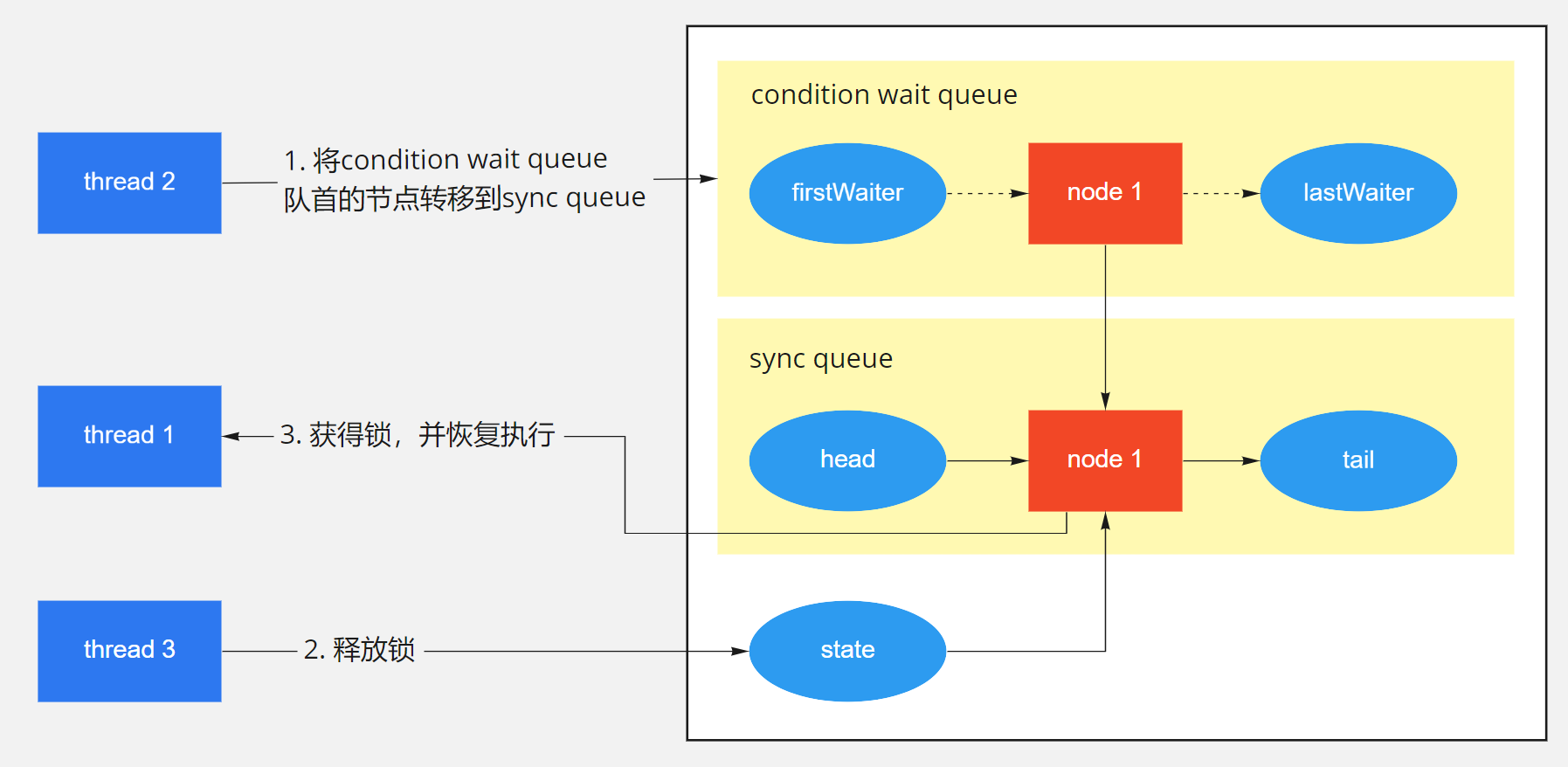
signal函数将condition wait queue队列中队首的线程节点转移等待获取锁的sync queue队列中。这样的话,await函数中调用isOnSyncQueue函数就会返回true,导致await函数进入最后一步重新获取锁的状态。
我们这里来详细解析一下condition wait queue和sync queue两个队列的设计原理。condition wait queue是等待消息的队列,因为阻塞队列为空而进入阻塞状态的take函数操作就是在等待阻塞队列不为空的消息。而sync queue队列则是等待获取锁的队列,take函数获得了消息,就可以运行了,但是它还必须等待获取锁之后才能真正进行运行状态。
signal函数其实就做了一件事情,就是不断尝试调用transferForSignal函数,将condition wait queue队首的一个节点转移到sync queue队列中,直到转移成功。因为一次转移成功,就代表这个消息被成功通知到了等待消息的节点。
signal函数的示意图如下所示。
🪟扩展
✅数组和链表有何区别?
从定义上讲:数组和链表都是数据的集合。
- 数组中每个元素都是连续的,通过下标进行访问,当我们获取到下标后,就可以随意访问数组中的值
- 链表中的元素则是不连续的,必须获得链表中某个元素后,才能访问该链表中元素的周围元素,不可以随意链表中的元素。链表分为单向链表,双向链表,环形链表等
从实现上来讲:
- 数组可以由一块连续区域的内存实现,其中,内存地址可以作为数组的下标,该地址中的值就是数组中元素的值。因为数组占用的是一块空间,所以数组的大小申请之后就会固定;
- 链表可以由不连续的内存存储实现,每个元素都会存储下一个元素的地址。(如果是双向链表的话,元素则会还会存储上个链表的地址)。因为链表中存储了元素的地址,所以链表可以在内存足够的情况下随意申请空间。
如图:
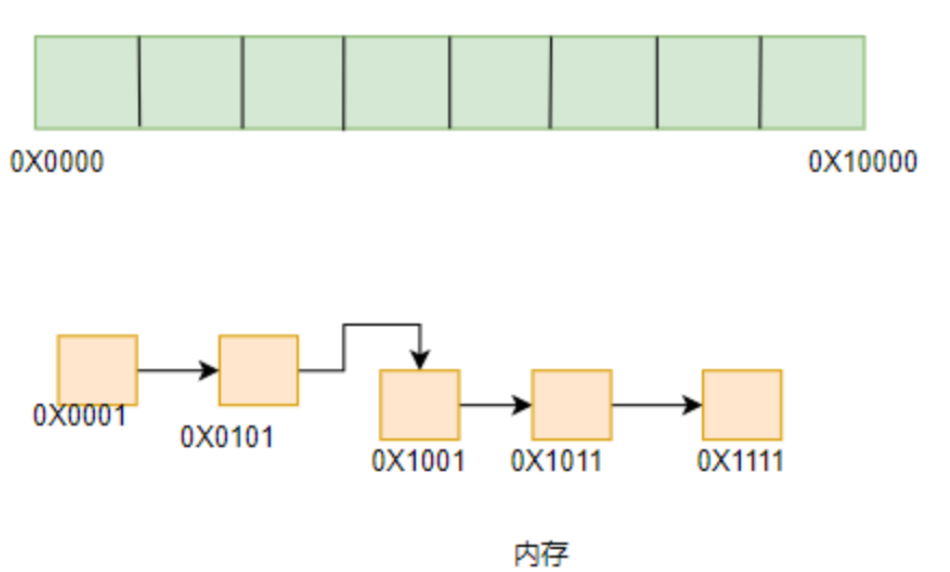
数组和链表的区别如下所示:
| 数组 | 链表 | |
|---|---|---|
| 内存中是否连续 | 是 | 否 |
| 查询效率 | 通过下标查是O(1) 通过数值查是O(n),如果是有序数组则O(logn) | O(n) |
| 占用空间 | 直接申请空间,当元素个数不确定时,容易浪费 | 相对数组来说会存储前后指针 大小和元素个数相同 |
| 插入/删除 | 数组需要移动n/2个元素 | 链表只需要修改指针 |





